Content from Introduction to Natural Language Processing
Last updated on 2024-05-12 | Edit this page
Estimated time: 10 minutes
Overview
Questions
- What are some common research applications of NLP?
- What are the basic concepts and terminology of NLP?
- How can I use NLP in my research field?
- How can I acquire data for NLP tasks?
Objectives
- Define natural language processing and its goals.
- Identify the main research applications and challenges of NLP.
- Explain the basic concepts and terminology of NLP, such as tokens, lemmas, and n-grams.
- Use some popular datasets and libraries to acquire data for NLP tasks.
1.1. Introduction to NLP Workshop
Natural Language Processing (NLP) is becoming a popular and robust tool for a wide range of research projects. In this episode, we embark on a journey to explore the transformative power of NLP tools in the realm of research.
It is tailored for researchers who are keen on harnessing the capabilities of NLP to enhance and expedite their work. Whether you are delving into text classification, extracting pivotal information, discerning sentiments, summarizing extensive documents, translating across languages, or developing sophisticated question-answering systems, this session will lay the foundational knowledge you need to leverage NLP effectively.
We will begin by delving into the Common Applications of NLP in Research, showcasing how these tools are not just theoretical concepts but practical instruments that drive forward today’s innovative research projects. From analyzing public sentiment to extracting critical data from a plethora of documents, NLP stands as a pillar in the modern researcher’s toolkit.
Prompt: “NLP for Research” [DALL-E
3]
Next, we’ll demystify the Basic Concepts and Terminology of NLP. Understanding these fundamental terms is crucial, as they form the building blocks of any NLP application. We’ll cover everything from the basics of a corpus to the intricacies of transformers, ensuring you have a solid grasp of the language used in NLP.
Finally, we’ll guide you through Data Acquisition: Dataset Libraries, where you’ll learn about the treasure troves of data available at your fingertips. We’ll compare different libraries and demonstrate how to access and utilize these resources through hands-on examples.
By the end of this episode, you will not only understand the significance of NLP in research but also be equipped with the knowledge to start applying these tools to your own projects. Prepare to unlock new potentials and streamline your research process with the power of NLP!
Discussion
Teamwork: What are some examples of NLP in your everyday life? Think of some situations where you interact with or use NLPs, such as online search, voice assistants, social media, etc. How do these examples demonstrate the usefulness of NLP in research projects?
Discussion
Teamwork: What are some examples of NLP in your daily research tasks? What are challenges of NLP that make it difficult, complex, and/or inaccurate?
1.2. Common Applications of NLP in Research
Sentiment Analysis is a powerful tool for researchers, especially in fields like market research, political science, and public health. It involves the computational identification of opinions expressed in text, categorizing them as positive, negative, or neutral.
In market research, for instance, sentiment analysis can be applied to product reviews to gauge consumer satisfaction: a study could analyze thousands of online reviews for a new smartphone model to determine the overall public sentiment. This can help companies identify areas of improvement or features that are well-received by consumers.
Information Extraction is crucial for quickly gathering specific information from large datasets. It is used extensively in legal research, medical research, and scientific studies to extract entities and relationships from texts.
In legal research, for example, information extraction can be used to sift through case law to find precedents related to a particular legal issue. A researcher could use NLP to extract instances of “negligence” from thousands of case files, aiding in the preparation of legal arguments.
Text Summarization helps researchers by providing concise summaries of lengthy documents, such as research papers or reports, allowing them to quickly understand the main points without reading the entire text.
In biomedical research, text summarization can assist in literature reviews by providing summaries of research articles. For example, a researcher could use an NLP model to summarize articles on gene therapy, enabling them to quickly assimilate key findings from a vast array of publications.
Topic Modeling is used to uncover latent topics within large volumes of text, which is particularly useful in fields like sociology and history to identify trends and patterns in historical documents or social media data.
For example, in historical research, topic modeling can reveal prevalent themes in primary source documents from a particular era. A historian might use NLP to analyze newspapers from the early 20th century to study public discourse around significant events like World War I.
Named Entity Recognition is a process where an algorithm takes a string of text (sentence or paragraph) and identifies relevant nouns (people, places, and organizations) that are mentioned in that string.
NER is used in many fields in NLP, and it can help answer many real-world questions, such as: Which companies were mentioned in the news article? Were specified products mentioned in complaints or reviews? Does the tweet (recently rebranded to X) contain the name of a person? Does the tweet contain this person’s location?
Challenges of NLP
One of the significant challenges in NLP is dealing with the ambiguity of language. Words or phrases can have multiple meanings, and determining the correct one based on context can be difficult for NLP systems. In a research paper discussing “bank erosion,” an NLP system might confuse “bank” with a financial institution rather than the geographical feature, leading to incorrect analysis.
This challenge leads to the fact that the classical NLP systems often struggle with contextual understanding which is crucial in text analysis tasks. This can lead to misinterpretation of the meaning and sentiment of the text. If a research paper mentions “novel results,” an NLP system might interpret “novel” as a literary work instead of “new” or “original,” which could mislead the analysis of the paper’s contributions.
- Python’s Natural Language Toolkit (NLTK) for sentiment analysis
- TextBlob, a library for processing textual data
- Stanford NER for named entity recognition
- spaCy, an open-source software library for advanced NLP
- Sumy, a Python library for automatic summarization of text documents
- BERT-based models for extractive and abstractive summarization
- Gensim for topic modeling and document similarity analysis
- MALLET, a Java-based package for statistical natural language processing
1.3. Basic Concepts and Terminology of NLP
Discussion
Teamwork: What are some of the basic concepts and terminology of natural language processing that you are familiar with or want to learn more about? Share your knowledge or questions with a partner or a small group, and try to explain or understand some of the key terms of natural language processing, such as tokens, lemmas, n-grams, etc.
Corpus: A corpus is a collection of written texts, especially the entire works of a particular author or a body of writing on a particular subject. In NLP, a corpus is used as a large and structured set of texts that can be used to perform statistical analysis and hypothesis testing, check occurrences, or validate linguistic rules within a specific language territory.
Token and Tokenization: Tokenization is the process of breaking a stream of text up into words, phrases, symbols, or other meaningful elements called tokens. The list of tokens becomes input for further processing such as parsing or text mining. Tokenization is useful in situations where certain characters or words need to be treated as a single entity, despite any spaces or punctuation that might separate them.
Stemming: Stemming is the process of reducing inflected (or sometimes derived) words to their word stem, base, or root form—generally a written word form. The idea is to remove affixes to get to the root form of the word. Stemming is often used in search engines for indexing words. Instead of storing all forms of a word, a search engine can store only the stems, greatly reducing the size of the index while increasing retrieval accuracy.
Lemmatization: Lemmatization, unlike Stemming, reduces the inflected words properly ensuring that the root word belongs to the language. In Lemmatization, the root word is called Lemma. A lemma is the canonical form, dictionary form, or citation form of a set of words. For example, runs, running, and running are all forms of the word run, therefore run is the lemma of all these words.
Part-of-Speech (PoS) Tagging: Part-of-speech tagging is the process of marking up a word in a text as corresponding to a particular part of speech, based on both its definition and its context. It is a necessary step before performing more complex NLP tasks like parsing or grammar checking.
Chunking: Chunking is a process of extracting phrases from unstructured text. Instead of just simple tokens that may not represent the actual meaning of the text, it’s also interested in extracting entities like noun phrases, verb phrases, etc. It’s basically a meaningful grouping of words or tokens.
Word Embeddings: Word embeddings are a type of word representation that allows words with similar meanings to have a similar representation. They are a distributed representation of text that is perhaps one of the key breakthroughs for the impressive performance of deep learning methods on challenging natural language processing problems.
Transformers: Transformers are models that handle the ordering of words and other elements in a language. They are designed to handle sequential data, such as natural language, for tasks such as translation and text summarization. They are the foundation of most recent advances in NLP, including models like BERT and GPT.
1.4. Data Acquisition: Dataset Libraries:
Different data libraries offer various datasets that are useful for training and testing NLP models. These libraries provide access to a wide range of text data, from literary works to social media posts, which can be used for tasks such as sentiment analysis, topic modeling, and more.
Natural Language Toolkit (NLTK): NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text-processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning.
spaCy: spaCy is a free, open-source library for advanced Natural Language Processing in Python. It’s designed specifically for production use and helps you build applications that process and “understand” large volumes of text. It can be used to build information extraction or natural language understanding systems or to pre-process text for deep learning.
Gensim: Gensim is a Python library for topic modeling, document indexing, and similarity retrieval with large corpora. Targeted at the NLP and information retrieval communities, Gensim is designed to handle large text collections using data streaming and incremental online algorithms, which differentiates it from most other machine learning software packages that only target batch and in-memory processing.
Hugging Face’s datasets: This library provides a simple command-line interface to download and pre-process any of the major public datasets (text datasets in 467 languages and dialects, etc.) provided on the HuggingFace Datasets Hub. It’s designed to let the community easily add and share new datasets. Hugging Face Datasets simplifies working with data for machine learning, especially NLP tasks. It provides a central hub to find and load pre-processed datasets, saving you time on data preparation. You can explore a vast collection of datasets for various tasks and easily integrate them with other Hugging Face libraries.
Data acquisition using Hugging Face datasets library. First, we start with installing the library:
PYTHON
pip install datasets
# To import the dataset, we can write:
from datasets import load_datasetUse load_dataset with the dataset identifier in quotes. For example, to load the SQuAD question answering dataset:
PYTHON
squad_dataset = load_dataset("squad")
# Use the info attribute to view the trainset information:
print(squad_dataset["train"].info)Each data point is a dictionary with keys corresponding to data elements (e.g., question, context). Access them using those keys within square brackets:
PYTHON
question = squad_dataset["train"][0]["question"]
context = squad_dataset["train"][0]["context"]We can use the print() function to see the output:
Challenge:
Q: Use the nltk library to acquire data for natural language processing tasks. You can use the following code to load the nltk library and download some popular datasets:
Choose one of the datasets from the nltk downloader, such as brown, reuters, or gutenberg, and load it using the nltk.corpus module. Then, print the name, size, and description of the dataset.
A: You can use the following code to access the dataset information: Use the nltk library to acquire data for NLP tasks. Import the necessary libraries:
Key Points
- Image datasets can be found online or created uniquely for your research question.
- Images consist of pixels arranged in a particular order.
- Image data is usually preprocessed before use in a CNN for efficiency, consistency, and robustness.
- Input data generally consists of three sets: a training set used to fit model parameters; a validation set used to evaluate the model fit on training data; and a test set used to evaluate the final model performance.
Content from Introduction to Text Preprocessing
Last updated on 2024-05-12 | Edit this page
Estimated time: 12 minutes
Overview
Questions
- How can I prepare data for NLP text analysis?
- How can I use spaCy for text preprocessing?
Objectives
- Define text preprocessing and its purpose for NLP tasks.
- Perform sentence segmentation, tokenization lemmatization, and stop-words removal, using spaCy.
Text preprocessing is the method of cleaning and preparing text data for use in NLP. This step is vital because it transforms raw data into a format that can be analyzed and used effectively by NLP algorithms.
2.1. Sentence Segmentation
Sentence segmentation divides a text into its constituent sentences, which is essential for understanding the structure and flow of the content. We start with a field-specific text example and see how it works. We can start with a paragraph about perovskite nanocrystals from the context of material engineering. Divide it into sentences.
We can use the open-source library, spaCy, to perform this task. First, we import the spaCy library:
Then we need to Load the English language model:
We can store our text here:
PYTHON
perovskite_text = "Perovskite nanocrystals are a class of semiconductor nanocrystals with unique properties that distinguish them from traditional quantum dots. These nanocrystals have an ABX3 composition, where 'A' can be cesium, methylammonium (MA), or formamidinium (FA); 'B' is typically lead or tin; and 'X' is a halogen ion like chloride, bromide, or iodide. Their remarkable optoelectronic properties, such as high photoluminescence quantum yields and tunable emission across the visible spectrum, make them ideal for applications in light-emitting diodes, lasers, and solar cells."Now we process the text with spaCy:
To extract sentences from the processed text we use the list() function:
We use for loop and print() function to output each sentence to show the segmentation:
Output: Perovskite nanocrystals are a class of semiconductor nanocrystals with unique properties that distinguish them from traditional quantum dots.
These nanocrystals have an ABX3 composition, where 'A' can be cesium, methylammonium (MA), or formamidinium (FA); 'B' is typically lead or tin; and 'X' is a halogen ion like chloride, bromide, or iodide.
Their remarkable optoelectronic properties, such as high photoluminescence quantum yields and tunable emission across the visible spectrum, make them ideal for applications in light-emitting diodes, lasers, and solar cells.Discussion
Q: Let’s try again by completing the code below to segment sentences from a paragraph about “your field of research”:
A:
PYTHON
import spacy
nlp = spacy.load("en_core_web_sm")
# Add the paragraph about your field of research here
text = "***" # varies based on your field of research
doc = nlp(text)
# Fill in the blank to extract sentences:
sentences = list(doc.sents)
# Fill in the blank to print each sentence
for sentence in sentences:
print(sentence.text) Discussion
Teamwork: Why is text preprocessing necessary for NLP tasks? Think of some examples of NLP tasks that require text preprocessing, such as sentiment analysis, machine translation, or text summarization. How does text preprocessing improve the performance and accuracy of these tasks?
Challenge
Q: Use the spaCy library to perform sentence segmentation and tokenization on the following text:
PYTHON
text: "The research (Ref. [1]) focuses on developing perovskite nanocrystals with a bandgap of 1.5 eV, suitable for solar cell applications!". Print the number of sentences and tokens in the text, and the list of sentences and tokens. You can use the following code to load the spaCy library and the English language model:
A:
PYTHON
import spacy
# Load the English language model:
nlp = spacy.load("en_core_web_sm")
# Define the text with marks, letters, and numbers:
text = "The research (Ref. [1]) focuses on developing perovskite nanocrystals with a bandgap of 1.5 eV, suitable for solar cell applications.!"
# Process the text with spaCy
doc = nlp(text)
# Print the original text:
print("Original text:", text)
# Sentence segmentation:
sentences = list(doc.sents)
# Print the sentences:
print("Sentences:")
for sentence in sentences:
print(sentence.text)
# Tokenization:
tokens = [token.text for token in doc]
# Print the tokens:
print("Tokens:")
print(tokens)2.2. Tokeniziation
As already mentioned, in the first episode, Tokenization breaks down text into individual words or tokens, which is a fundamental step for many NLP tasks.
Discussion
Teamwork: To better understand how it works let’s Match tokens from the provided paragraph about perovskite nanocrystals with similar tokens from another scientific text. This helps in understanding the common vocabulary used in the scientific literature. Using the sentences we listed in the previous section, we can see how Tokenization performs. Assuming ‘sentences’ is a list of sentences from the previous example, choose a sentence to tokenize:
PYTHON
sentence_to_tokenize = sentences[0]
# Tokenize the chosen sentence by using a list comprehension:
tokens = [token.perovskite_text for token in sentence_to_tokenize]
# We can print the tokens:
print(tokens)Output: [‘Perovskite’, ‘nanocrystals’, ‘are’, ‘a’, ‘class’, ‘of’, ‘semiconductor’, ‘nanocrystals’, ‘with’, ‘unique’, ‘properties’, ‘that’, ‘distinguish’, ‘them’, ‘from’, ‘traditional’, ‘quantum’, ‘dots’, ‘.’]
Tokenization is not just about splitting text into words; it’s about understanding the boundaries of words and symbols in different contexts, which can vary greatly between languages and even within the same language in different settings.
Callout
Tokenization is very important for text analysis tasks such as sentiment analysis. Here we can compare two different texts from different fields and see how their associated tokens are different:
Now, we can add a new text from the trading context for comparison. Tokenization of a trading text can be performed similarly to the previous text.
PYTHON
trading_text = "Trading strategies often involve analyzing patterns and executing trades based on predicted market movements. Successful traders analyze trends and volatility to make informed decisions."
trading_tokens = [token.text for token in nlp(trading_text)]We can see the results by using the print() function. The tokens from both texts:
Output:
Perovskite Tokens: ['Perovskite', 'nanocrystals', 'are', 'a', 'class', 'of', 'semiconductor', 'nanocrystals', 'with', 'unique', 'properties', 'that', 'distinguish', 'them', 'from', 'traditional', 'quantum', 'dots', '.']
Trading Tokens: ['Trading', 'strategies', 'often', 'involve', 'analyzing', 'patterns', 'and', 'executing', 'trades', 'based', 'on', 'predicted', 'market', 'movements', '.', 'Successful', 'traders', 'analyze', 'trends', 'and', 'volatility', 'to', 'make', 'informed', 'decisions', '.']The tokens from the perovskite text will be specific to materials science, while the trading tokens will include terms related to market analysis. The scientific texts may use more complex and compound words while trading texts might include more action-oriented and analytical language. This comparison helps in understanding the specialized language used in different fields.
2.3. Stemming and Lemmatization
Stemming and lemmatization are techniques used to reduce words to their base or root form, aiding in the normalization of text. As discussed in the previous episode, these two methods are different. Decide whether stemming or lemmatization would be more appropriate for analyzing a set of research texts on perovskite nanocrystals.
Discussion
Teamwork: From the differences between lemmatization and stemming that we learned in the last episode, which technique will you select to get more accurate text analysis results? Explain why?
Following our initial example for Tokenization, we can see how lemmatization works. We start with processing the text with spaCy to perform lemmatization:
We can print the original text and the lemmatized text:
Output:
Original Text: Perovskite nanocrystals are a class of semiconductor nanocrystals with unique properties that distinguish them from traditional quantum dots. These nanocrystals have an ABX3 composition, where ‘A’ can be cesium, methylammonium (MA), or formamidinium (FA); ‘B’ is typically lead or tin; and ‘X’ is a halogen ion like chloride, bromide, or iodide. Their remarkable optoelectronic properties, such as high photoluminescence quantum yields and tunable emission across the visible spectrum, make them ideal for applications in light-emitting diodes, lasers, and solar cells.
Lemmatized Text: Perovskite nanocrystal be a class of semiconductor nanocrystal with unique property that distinguish they from traditional quantum dot . these nanocrystal have an ABX3 composition , where ’ A ’ can be cesium , methylammonium ( MA ) , or formamidinium ( FA ) ; ’ b ’ be typically lead or tin ; and ’ x ’ be a halogen ion like chloride , bromide , or iodide . their remarkable optoelectronic property , such as high photoluminescence quantum yield and tunable emission across the visible spectrum , make they ideal for application in light - emit diode , laser , and solar cell .
Callout
The spaCy library does not have stemming capabilities and if we want to compare stemming and lemmatization, we also need to use another language processing library called NLTK (refer to episode 1).
Based on what we just learned let’s compare lemmatization and stemming. First, we need to import the necessary libraries for stemming and lemmatization:
Next, we can create an instance of the PorterStemmer for NLTK and load the English language model for spaCy (similar to what we did earlier in this episode).
We can conduct stemming and lemmatization with identical text data:
text = ” Perovskite nanocrystals are a class of semiconductor nanocrystals with unique properties that distinguish them from traditional quantum dots. These nanocrystals have an ABX3 composition, where ‘A’ can be cesium, methylammonium (MA), or formamidinium (FA); ‘B’ is typically lead or tin; and ‘X’ is a halogen ion like chloride, bromide, or iodide. Their remarkable optoelectronic properties, such as high photoluminescence quantum yields and tunable emission across the visible spectrum, make them ideal for applications in light-emitting diodes, lasers, and solar cells.” Before we can stem or lemmatize, we need to tokenize the text.
PYTHON
from nltk.tokenize import word_tokenize
tokens = word_tokenize(text)
# Apply stemming to each token:
stemmed_tokens = [stemmer.stem(token) for token in tokens]For lemmatization, we process the text with spaCy and extract the lemma for each token:
Finally, we can compare the stemmed and lemmatized tokens:
PYTHON
print("Original Tokens:", tokens)
print("Stemmed Tokens:", stemmed_tokens)
print("Lemmatized Tokens:", lemmatized_tokens)Original Tokens: [‘Perovskite’, ‘nanocrystals’, ‘are’, ‘a’, ‘class’, ‘of’, ‘semiconductor’, ‘nanocrystals’, ‘with’, ‘unique’, ‘properties’, ‘that’, ‘distinguish’, ‘them’, ‘from’, ‘traditional’, ‘quantum’, ‘dots’, ‘.’, ‘These’, ‘nanocrystals’, ‘have’, ‘an’, ‘ABX3’, ‘composition’, ‘,’, ‘where’, “‘“, ‘A’,”’”, ‘can’, ‘be’, ‘cesium’, ‘,’, ‘methylammonium’, ‘(’, ‘MA’, ‘)’, ‘,’, ‘or’, ‘formamidinium’, ‘(’, ‘FA’, ‘)’, ‘;’, “‘“, ‘B’,”’”, ‘is’, ‘typically’, ‘lead’, ‘or’, ‘tin’, ‘;’, ‘and’, “‘“, ‘X’,”’”, ‘is’, ‘a’, ‘halogen’, ‘ion’, ‘like’, ‘chloride’, ‘,’, ‘bromide’, ‘,’, ‘or’, ‘iodide’, ‘.’, ‘Their’, ‘remarkable’, ‘optoelectronic’, ‘properties’, ‘,’, ‘such’, ‘as’, ‘high’, ‘photoluminescence’, ‘quantum’, ‘yields’, ‘and’, ‘tunable’, ‘emission’, ‘across’, ‘the’, ‘visible’, ‘spectrum’, ‘,’, ‘make’, ‘them’, ‘ideal’, ‘for’, ‘applications’, ‘in’, ‘light-emitting’, ‘diodes’, ‘,’, ‘lasers’, ‘,’, ‘and’, ‘solar’, ‘cells’, ‘.’]
Stemmed Tokens: [‘perovskit’, ‘nanocryst’, ‘are’, ‘a’, ‘class’, ‘of’, ‘semiconductor’, ‘nanocryst’, ‘with’, ‘uniqu’, ‘properti’, ‘that’, ‘distinguish’, ‘them’, ‘from’, ‘tradit’, ‘quantum’, ‘dot’, ‘.’, ‘these’, ‘nanocryst’, ‘have’, ‘an’, ‘abx3’, ‘composit’, ‘,’, ‘where’, “‘“, ‘a’,”’”, ‘can’, ‘be’, ‘cesium’, ‘,’, ‘methylammonium’, ‘(’, ‘ma’, ‘)’, ‘,’, ‘or’, ‘formamidinium’, ‘(’, ‘fa’, ‘)’, ‘;’, “‘“, ‘b’,”’”, ‘is’, ‘typic’, ‘lead’, ‘or’, ‘tin’, ‘;’, ‘and’, “‘“, ‘x’,”’”, ‘is’, ‘a’, ‘halogen’, ‘ion’, ‘like’, ‘chlorid’, ‘,’, ‘bromid’, ‘,’, ‘or’, ‘iodid’, ‘.’, ‘their’, ‘remark’, ‘optoelectron’, ‘properti’, ‘,’, ‘such’, ‘as’, ‘high’, ‘photoluminesc’, ‘quantum’, ‘yield’, ‘and’, ‘tunabl’, ‘emiss’, ‘across’, ‘the’, ‘visibl’, ‘spectrum’, ‘,’, ‘make’, ‘them’, ‘ideal’, ‘for’, ‘applic’, ‘in’, ‘light-emit’, ‘diod’, ‘,’, ‘laser’, ‘,’, ‘and’, ‘solar’, ‘cell’, ‘.’]
Lemmatized Tokens: [‘Perovskite’, ‘nanocrystal’, ‘be’, ‘a’, ‘class’, ‘of’, ‘semiconductor’, ‘nanocrystal’, ‘with’, ‘unique’, ‘property’, ‘that’, ‘distinguish’, ‘they’, ‘from’, ‘traditional’, ‘quantum’, ‘dot’, ‘.’, ‘these’, ‘nanocrystal’, ‘have’, ‘an’, ‘ABX3’, ‘composition’, ‘,’, ‘where’, “‘“, ‘A’,”’”, ‘can’, ‘be’, ‘cesium’, ‘,’, ‘methylammonium’, ‘(’, ‘MA’, ‘)’, ‘,’, ‘or’, ‘formamidinium’, ‘(’, ‘FA’, ‘)’, ‘;’, “‘“, ‘b’,”’”, ‘be’, ‘typically’, ‘lead’, ‘or’, ‘tin’, ‘;’, ‘and’, “‘“, ‘x’,”’”, ‘be’, ‘a’, ‘halogen’, ‘ion’, ‘like’, ‘chloride’, ‘,’, ‘bromide’, ‘,’, ‘or’, ‘iodide’, ‘.’, ‘their’, ‘remarkable’, ‘optoelectronic’, ‘property’, ‘,’, ‘such’, ‘as’, ‘high’, ‘photoluminescence’, ‘quantum’, ‘yield’, ‘and’, ‘tunable’, ‘emission’, ‘across’, ‘the’, ‘visible’, ‘spectrum’, ‘,’, ‘make’, ‘they’, ‘ideal’, ‘for’, ‘application’, ‘in’, ‘light’, ‘-’, ‘emit’, ‘diode’, ‘,’, ‘laser’, ‘,’, ‘and’, ‘solar’, ‘cell’, ‘.’]
We can see how stemming often cuts off the end of words, sometimes resulting in non-words, while lemmatization returns the base or dictionary form of the word. For example, stemming might reduce “properties” to “properti” while lemmatization would correctly identify the lemma as “property”. Lemmatization provides a more readable and meaningful result, which is particularly useful in NLP tasks that require understanding the context and meaning of words.
Challenge
Q: Use the spaCy library to perform lemmatization on the following text: “Perovskite nanocrystals are a promising class of materials for optoelectronic applications due to their tunable bandgaps and high photoluminescence efficiencies.” Print the original text and the lemmatized text. You can use the following code to load the spacy library and the English language model:
A:
PYTHON
import spacy
# Load the English language model:
nlp = spacy.load("en_core_web_sm")
# Define the text:
text = "Perovskite nanocrystals are a promising class of materials for optoelectronic applications due to their tunable bandgaps and high photoluminescence efficiencies."
# Process the text with spaCy:
doc = nlp(text)
# Print the original text:
print("Original text:", text)
# Print the lemmatized text:
lemmatized_text = " ".join([token.lemma_ for token in doc])
print("Lemmatized text:", lemmatized_text)2.4. Stop-words Removal
Removing stop-words, which are common words that add little value to the analysis (such as ‘and’ and ‘the’), helps focus on the important content. Assuming ‘doc’ is the processed text from the previous example for ‘perovskite nanocrystals’, we can define a list to hold non-stop words list comprehensions:
PYTHON
filtered_sentence = [word for word in doc if not word.is_stop]
# print the filtered sentence and see how it is changed:
print("Filtered sentence:", filtered_sentence)Output: Filtered sentence: [Perovskite, nanocrystals, class, semiconductor, nanocrystals, unique, properties, distinguish, traditional, quantum, dots, ., nanocrystals, ABX3, composition, ,, ‘,’, cesium, ,, methylammonium, (, MA, ), ,, formamidinium, (, FA, ), ;, ‘, B,’, typically, lead, tin, ;, ‘, X,’, halogen, ion, like, chloride, ,, bromide, ,, iodide, ., remarkable, optoelectronic, properties, ,, high, photoluminescence, quantum, yields, tunable, emission, visible, spectrum, ,, ideal, applications, light, -, emitting, diodes, ,, lasers, ,, solar, cells, .]
List comprehensions provide a convenient method for rapidly generating lists based on a straightforward condition.
Challenge
Q: To see how list comprehensions are created, fill in the missing parts of the code to remove stop-words from a given sentence.
Warning!
While stopwords are often removed to improve analysis, they can be important for certain tasks like sentiment analysis, where the word ‘not’ can change the entire meaning of a sentence.
It is important to note that tokenization is just the beginning. In modern NLP, vectorization, and embeddings play a pivotal role in capturing the context and meaning of text.
Vectorization is the process of converting tokens into a numerical format that machine learning models can understand. This often involves creating a bag-of-words model, where each token is represented by a unique number in a vector. Embeddings are advanced representations where words are mapped to vectors of real numbers. They capture not just the presence of tokens but also the semantic relationships between them. This is achieved through techniques like Word2Vec, GloVe, or BERT, which we will explore in the second part of our workshop.
These embeddings allow models to understand the text in a more nuanced way, leading to better performance on tasks such as sentiment analysis, machine translation, and more.
Stay tuned for our next session, where we will dive deeper into how we can use vectorization and embeddings to enhance our NLP models and truly capture the richness of language.
Key Points
- Text preprocessing is essential for cleaning and standardizing text data.
- Techniques like sentence segmentation, tokenization, stemming, and lemmatization are fundamental to text preprocessing.
- Removing stop-words helps in focusing on the important words in text analysis.
- Tokenization splits sentences into tokens, which are the basic units for further processing.
Content from Text Analysis
Last updated on 2024-05-15 | Edit this page
Estimated time: 12 minutes
Overview
Questions
- What are text analysis methods?
- How can I perform text analysis?
Objectives
- Define objectives associated with each one of the text analysis techniques.
- Implement named entity recognition, and topic modeling using Python libraries and frameworks, such as NLTK, and Gensim.
3.1. Introduction to Text-Analysis
In this episode, we will learn how to analyze text data for NLP tasks. We will explore some common techniques and methods for text analysis, such as named entity recognition, topic modeling, and text summarization. We will use some popular libraries and frameworks, such as spaCy, NLTK, and Gensim, to implement these techniques and methods.
Discussion
Teamwork: What are some of the goals of text analysis for NLP tasks in your research field (e.g. material science)? Think of some examples of NLP tasks that require text analysis, such as literature review, patent analysis, or material discovery. How does text analysis help to achieve these goals?
Discussion
Teamwork: Name some of the common techniques in text analysis and associating libraries. Briefly explain how they differ from each other in terms of their objectives and required libraries.
3.1. Named Entity Recognition
Named Entity Recognition is a process of identifying and classifying key elements in text into predefined categories. The categories could be names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc. Next, let’s discuss how it works.
Discussion
Teamwork: Discuss what tasks can be done with NER.
A: NER can help with 1) categorizing resumes, 2) categorizing customer feedback, 3) categorizing research papers, etc.
Using a text example from Wikipedia can help us to see how NER works. Note that the spaCy library is a common framework here as well. Thus, first, we make sure that the library is installed and imported:
Create an NLP model (nlp) and download the small English model from spaCy that is suitable for general tasks.
Create a variable to store your text and then apply the model to process your text (text from Wikipedia):
text = “Australian Shares Exchange Ltd (ASX) is an Australian public company that operates Australia’s primary shares exchange, the Australian Shares Exchange (sometimes referred to outside of Australia as, or confused within Australia as, The Sydney Stock Exchange, a separate entity). The ASX was formed on 1 April 1987, through incorporation under legislation of the Australian Parliament as an amalgamation of the six state securities exchanges, and merged with the Sydney Futures Exchange in 2006. Today, ASX has an average daily turnover of A$4.685 billion and a market capitalization of around A$1.6 trillion, making it one of the world’s top 20 listed exchange groups, and the largest in the southern hemisphere. ASX Clear is the clearing house for all shares, structured products, warrants and, ASX Equity Derivatives.”
Use for loop to print all the named entities in the document:
The results will be:
output:
Australian Shares Exchange Ltd ORG
ASX ORG
Australian NORP
Australia GPE
the Australian Shares Exchange ORG
Australia GPE
Australia GPE
The Sydney Stock Exchange ORG
ASX ORG
1 April 1987 DATE
the Australian Parliament ORG
six CARDINAL
the Sydney Futures Exchange ORG
2006 DATE
Today DATE
ASX ORG
A$4.685 billion MONEY
around A$1.6 trillion MONEY
20 CARDINAL
Challenge
Q: How can you interpret the labels in the output?
Challenge
Q: Can we also use other libraries for NER analysis? Use the NLTK library to perform named entity recognition on the following text:
text = ” Perovskite nanocrystals have emerged as a promising class of materials for next-generation optoelectronic devices due to their unique properties. Their crystal structure allows for tunable bandgaps, which are the energy differences between occupied and unoccupied electronic states. This tunability enables the creation of materials that can absorb and emit light across a wide range of the electromagnetic spectrum, making them suitable for applications like solar cells, light-emitting diodes (LEDs), and lasers. Additionally, perovskite nanocrystals exhibit high photoluminescence efficiencies, meaning they can efficiently convert absorbed light into emitted light, further adding to their potential for various optoelectronic applications.”
A: Download the necessary NLTK resources and import the required toolkit:
PYTHON
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('maxent_ne_chunker')Store the text:
text = “Perovskite nanocrystals have emerged as a promising class of materials for next-generation optoelectronic devices due to their unique properties. Their crystal structure allows for tunable bandgaps, which are the energy differences between occupied and unoccupied electronic states. This tunability enables the creation of materials that can absorb and emit light across a wide range of the electromagnetic spectrum, making them suitable for applications like solar cells, light-emitting diodes (LEDs), and lasers. Additionally, perovskite nanocrystals exhibit high photoluminescence efficiencies, meaning they can efficiently convert absorbed light into emitted light, further adding to their potential for various optoelectronic applications.”
PYTHON
# Tokenize the text:
tokens = nltk.word_tokenize(text)
# Assign part-of-speech tags:
pos_tags = nltk.pos_tag(tokens)
# Perform named entity recognition:
named_entities = nltk.ne_chunk(pos_tags)
# Print the original text:
print("Original Text:")
print(text)
# Print named entities and their types:
print("\nNamed Entities:")
for entity in named_entities:
if type(entity) == nltk.Tree:
print(f"Entity: {''.join(word for word, _ in entity.leaves())}, Type: {entity.label()}")Original Text: Perovskite nanocrystals have emerged as a promising class of materials for next-generation optoelectronic devices due to their unique properties. Their crystal structure allows for tunable bandgaps, which are the energy differences between occupied and unoccupied electronic states. This tunability enables the creation of materials that can absorb and emit light across a wide range of the electromagnetic spectrum, making them suitable for applications like solar cells, light-emitting diodes (LEDs), and lasers. Additionally, perovskite nanocrystals exhibit high photoluminescence efficiencies, meaning they can efficiently convert absorbed light into emitted light, further adding to their potential for various optoelectronic applications.
- Named Entities:
- Entity: Perovskite, Type: ORGANIZATION
- Entity: light-emitting diodes (LEDs), Type: ORGANIZATION
[((‘Perovskite’, ‘NNP’), ‘ORGANIZATION’), (‘nanocrystals’, ‘NNP’), (‘have’, ‘VBP’), (‘emerged’, ‘VBD’), (‘as’, ‘IN’), (‘a’, ‘DT’), (‘promising’, ‘JJ’), (‘class’, ‘NN’), (‘of’, ‘IN’), (‘materials’, ‘NNS’), (‘for’, ‘IN’), (‘next-generation’, ‘JJ’), (‘optoelectronic’, ‘JJ’), (‘devices’, ‘NNS’), (‘due’, ‘IN’), (‘to’, ‘TO’), (‘their’, ‘PRP\('), ('unique', 'JJ'), ('properties', 'NNS'), ('.', '.'), ('Their', 'PRP\)’), (‘crystal’, ‘NN’), (‘structure’, ‘NN’), (‘allows’, ‘VBZ’), (‘for’, ‘IN’), (‘tunable’, ‘JJ’), (‘bandgaps’, ‘NNS’), (‘,’, ‘,’), (‘which’, ‘WDT’), (‘are’, ‘VBP’), (‘the’, ‘DT’), (‘energy’, ‘NN’), (‘differences’, ‘NNS’), (‘between’, ‘IN’), (‘occupied’, ‘VBN’), (‘and’, ‘CC’), (‘unoccupied’, ‘VBN’), (‘electronic’, ‘JJ’), (‘states’, ‘NNS’), (‘.’, ‘.’), (‘This’, ‘DT’), (‘tunability’, ‘NN’), (‘enables’, ‘VBZ’), (‘the’, ‘DT’), (‘creation’, ‘NN’), (‘of’, ‘IN’), (‘materials’, ‘NNS’), (‘that’, ‘WDT’), (‘can’, ‘MD’), (‘absorb’, ‘VB’), (‘and’, ‘CC’), (‘emit’, ‘VB’), (‘light’, ‘NN’), (‘across’, ‘IN’), (‘a’, ‘DT’), (‘wide’, ‘JJ’), (‘range’, ‘NN’), (‘of’, ‘IN’), (‘the’, ‘DT’), (‘electromagnetic’, ‘JJ’), (‘spectrum’, ‘NN’), (‘,’, ‘,’), (‘making’, ‘VBG’), (‘them’, ‘PRP’), (‘suitable’, ‘JJ’), (‘for’, ‘IN’), (‘applications’, ‘NNS’), (‘like’, ‘IN’), (‘solar’, ‘JJ’), (‘cells’, ‘NNS’), (‘,’, ‘,’), (‘light-emitting’, ‘JJ’), (‘diodes’, ‘NNS’), (‘(’, ‘(’, ‘LEDs’, ‘NNPS’), ‘)’, ‘)’), (‘and’, ‘CC’), (‘lasers’, ‘NNS’), (‘.’, ‘.’), (‘Additionally’, ‘RB’), (‘,’, ‘,’), (‘perovskite’, ‘NNP’), (‘nanocrystals’, ‘NNP’), (‘exhibit’, ‘VBP’), (‘high’, ‘JJ’), (‘photoluminescence’, ‘NN’), (‘efficiencies’, ‘NNS’), (‘,’, ‘,’), (‘meaning’, ‘VBG’), (‘they’, ‘PRP’), (‘can’, ‘MD’), (‘efficiently’, ‘RB’), (‘convert’, ‘VB’), (‘absorbed’, ‘VBN’), (‘light’, ‘NN’), (‘into’, ‘IN’), (‘emitted’, ‘VBN’), (‘light’, ‘NN’), (‘,’, ‘,’), (‘further’, ‘RB’), (‘adding’, ‘VBG’), (‘to’, ‘TO’), (‘their’, ‘PRP$’), (‘potential’, ‘NN’), (‘for’, ‘IN’), (‘various’, ‘JJ’), (‘optoelectronic’, ‘JJ’), (‘applications’, ‘NNS’), (‘.’, ‘.’)]
Why NER?
When do we need to perform NER for your research?
NER helps in quickly finding specific information in large datasets, which is particularly useful in research fields for categorizing the text based on the entities. NER is also called entity chunking and entity extraction.
3.2. Topic Modeling
Topic Modeling is an unsupervised model for discovering the abstract “topics” that occur in a collection of documents. It is useful in understanding the main themes of a large corpus of text. To better understand this and to find the connection between concepts we have learned so far, let’s match the following terms to their brief definitions:
Challenge
Teamwork: To better understand this and to find the connection between concepts we have learned so far, let’s match the following terms to their brief definitions:
Callout
There are some new concepts in this section that are new to you. Although a detailed explanation of these concepts is out of the scope of this workshop we learn their basic definitions. You already learned a few of them in the earlier activity. Another one is Bag-of-words. We will learn more about Bag-of-words (BoW) in episode 5. BoW is defined as a representation of text that describes the occurrence of words within a document. It is needed in the topic modeling analysis to view the frequency of the words in a document regardless of the order of the words in the text.
To see how Topic Modeling can help us in action to classify a text, let’s see the following example. We need to install the Gensim library and import the necessary modules:
PYTHON
pip install genism
import gensim
from gensim import corpora
from gensim.models import LdaModel
from gensim.utils import simple_preprocess
at this stage, we preprocess including the text tokenization (text from Wikipedia):
text = “Australian Shares Exchange Ltd (ASX) is an Australian public company that operates Australia’s primary shares exchange, the Australian Shares Exchange (sometimes referred to outside of Australia as, or confused within Australia as, The Sydney Stock Exchange, a separate entity). The ASX was formed on 1 April 1987, through incorporation under legislation of the Australian Parliament as an amalgamation of the six state securities exchanges and merged with the Sydney Futures Exchange in 2006. Today, ASX has an average daily turnover of A$4.685 billion and a market capitalisation of around A$1.6 trillion, making it one of the world’s top 20 listed exchange groups, and the largest in the southern hemisphere. ASX Clear is the clearing house for all shares, structured products, warrants and ASX Equity Derivatives. ASX Group[3] is a market operator, clearing house and payments system facilitator. It also oversees compliance with its operating rules, promotes standards of corporate governance among Australia’s listed companies and helps to educate retail investors. Australia’s capital markets. Financial development – Australia was ranked 5th out of 57 of the world’s leading financial systems and capital markets by the World Economic Forum; Equity market – the 8th largest in the world (based on free-float market capitalisation) and the 2nd largest in Asia-Pacific, with A$1.2 trillion market capitalisation and average daily secondary trading of over A$5 billion a day; Bond market – 3rd largest debt market in the Asia Pacific; Derivatives market – largest fixed income derivatives in the Asia-Pacific region; Foreign exchange market – the Australian foreign exchange market is the 7th largest in the world in terms of global turnover, while the Australian dollar is the 5th most traded currency and the AUD/USD the 4th most traded currency pair; Funds management – Due in large part to its compulsory superannuation system, Australia has the largest pool of funds under management in the Asia-Pacific region, and the 4th largest in the world. Its primary markets are the AQUA Markets. Regulation. The Australian Securities & Investments Commission (ASIC) has responsibility for the supervision of real-time trading on Australia’s domestic licensed financial markets and the supervision of the conduct by participants (including the relationship between participants and their clients) on those markets. ASIC also supervises ASX’s own compliance as a public company with ASX Listing Rules. ASX Compliance is an ASX subsidiary company that is responsible for monitoring and enforcing ASX-listed companies’ compliance with the ASX operating rules. The Reserve Bank of Australia (RBA) has oversight of the ASX’s clearing and settlement facilities for financial system stability. In November 1903 the first interstate conference was held to coincide with the Melbourne Cup. The exchanges then met on an informal basis until 1937 when the Australian Associated Stock Exchanges (AASE) was established, with representatives from each exchange. Over time the AASE established uniform listing rules, broker rules, and commission rates. Trading was conducted by a call system, where an exchange employee called the names of each company and brokers bid or offered on each. In the 1960s this changed to a post system. Exchange employees called”chalkies” wrote bids and offers in chalk on blackboards continuously, and recorded transactions made. The ASX (Australian Stock Exchange Limited) was formed in 1987 by legislation of the Australian Parliament which enabled the amalgamation of six independent stock exchanges that formerly operated in the state capital cities. After demutualisation, the ASX was the first exchange in the world to have its shares quoted on its own market. The ASX was listed on 14 October 1998.[7] On 7 July 2006 the Australian Stock Exchange merged with SFE Corporation, holding company for the Sydney Futures Exchange. Trading system. ASX Group has two trading platforms – ASX Trade,[12] which facilitates the trading of ASX equity securities and ASX Trade24 for derivative securities trading. All ASX equity securities are traded on screen on ASX Trade. ASX Trade is a NASDAQ OMX ultra-low latency trading platform based on NASDAQ OMX’s Genium INET system, which is used by many exchanges around the world. It is one of the fastest and most functional multi-asset trading platforms in the world, delivering latency down to ~250 microseconds. ASX Trade24 is ASX global trading platform for derivatives. It is globally distributed with network access points (gateways) located in Chicago, New York, London, Hong Kong, Singapore, Sydney and Melbourne. It also allows for true 24-hour trading, and simultaneously maintains two active trading days which enables products to be opened for trading in the new trading day in one time zone while products are still trading under the previous day. Opening times. The normal trading or business days of the ASX are week-days, Monday to Friday. ASX does not trade on national public holidays: New Year’s Day (1 January), Australia Day (26 January, and observed on this day or the first business day after this date), Good Friday (that varies each year), Easter Monday, Anzac day (25 April), Queen’s birthday (June), Christmas Day (25 December) and Boxing Day (26 December). On each trading day there is a pre-market session from 7:00 am to 10:00 am AEST and a normal trading session from 10:00 am to 4:00 pm AEST. The market opens alphabetically in single-price auctions, phased over the first ten minutes, with a small random time built in to prevent exact prediction of the first trades. There is also a single-price auction between 4:10 pm and 4:12 pm to set the daily closing prices. Settlement. Security holders hold shares in one of two forms, both of which operate as uncertificated holdings, rather than through the issue of physical share certificates: Clearing House Electronic Sub-register System (CHESS). The investor’s controlling participant (normally a broker) sponsors the client into CHESS. The security holder is given a “holder identification number” (HIN) and monthly statements are sent to the security holder from the CHESS system when there is a movement in their holding that month. Issuer-sponsored. The company’s share register administers the security holder’s holding and issues the investor with a security-holder reference number (SRN) which may be quoted when selling. Holdings may be moved from issuer-sponsored to CHESS or between different brokers by electronic message initiated by the controlling participant. Short selling. Main article: Short (finance). Short selling of shares is permitted on the ASX, but only among designated stocks and with certain conditions: ASX trading participants (brokers) must report all daily gross short sales to ASX. The report will aggregate the gross short sales as reported by each trading participant at an individual stock level. ASX publishes aggregate gross short sales to ASX participants and the general public.[13] Many brokers do not offer short selling to small private investors. LEPOs can serve as an equivalent, while contracts for difference (CFDs) offered by third-party providers are another alternative. In September 2008, ASIC suspended nearly all forms of short selling due to concerns about market stability in the ongoing global financial crisis.[14][15] The ban on covered short selling was lifted in May 2009.[16] Also, in the biggest change for ASX in 15 years, ASTC Settlement Rule 10.11.12 was introduced, which requires the broker to provide stocks when settlement is due, otherwise the broker must buy the stock on the market to cover the shortfall. The rule requires that if a Failed Settlement Shortfall exists on the second business day after the day on which the Rescheduled Batch Instruction was originally scheduled for settlement (that is, generally on T+5), the delivering settlement participant must either: close out the Failed Settlement Shortfall on the next business day by purchasing the number of Financial Products of the relevant class equal to the shortfall; or acquire under a securities lending arrangement the number of Financial Products of the relevant class equal to the shortfall and deliver those Financial Products in Batch Settlement no more than two business days later.[17] Options. Options on leading shares are traded on the ASX, with standardised sets of strike prices and expiry dates. Liquidity is provided by market makers who are required to provide quotes. Each market maker is assigned two or more stocks. A stock can have more than one market maker, and they compete with one another. A market maker may choose one or both of: Make a market continuously, on a set of 18 options. Make a market in response to a quote request, in any option up to 9 months out. In both cases there is a minimum quantity (5 or 10 contracts depending on the shares) and a maximum spread permitted. Due to the higher risks in options, brokers must check clients’ suitability before allowing them to trade options. Clients may both take (i.e. buy) and write (i.e. sell) options. For written positions, the client must put up margin. Interest rate market. The ASX interest rate market is the set of corporate bonds, floating rate notes, and bond-like preference shares listed on the exchange. These securities are traded and settled in the same way as ordinary shares, but the ASX provides information such as their maturity, effective interest rate, etc., to aid comparison.[18] Futures. The Sydney Futures Exchange (SFE) was the 10th largest derivatives exchange in the world, providing derivatives in interest rates, equities, currencies and commodities. The SFE is now part of ASX and its most active products are: SPI 200 Futures – Futures contracts on an index representing the largest 200 stocks on the Australian Stock Exchange by market capitalisation. AU 90-day Bank Accepted Bill Futures – Australia’s equivalent of T-Bill futures. 3-Year Bond Futures – Futures contracts on Australian 3-year bonds. 10-Year Bond Futures – Futures contracts on Australian 10-year bonds. The ASX trades futures over the ASX 50, ASX 200 and ASX property indexes, and over grain, electricity and wool. Options over grain futures are also traded. Market indices. The ASX maintains stock indexes concerning stocks traded on the exchange in conjunction with Standard & Poor’s. There is a hierarchy of index groups called the S&P/ASX 20, S&P/ASX 50, S&P/ASX 100, S&P/ASX 200 and S&P/ASX 300, notionally containing the 20, 50, 100, 200 and 300 largest companies listed on the exchange, subject to some qualifications. Sharemarket Game. The ASX Sharemarket Game give members of the public and secondary school students the chance to learn about investing in the sharemarket using real market prices. Participants receive a hypothetical $50,000 to buy and sell shares in 150 companies and track the progress of their investments over the duration of the game.[19] Merger talks with SGX. ASX was (25 October 2010) in merger talks with Singapore Exchange (SGX). While there was an initial expectation that the merger would have created a bourse with a market value of US$14 billion,[20] this was a misconception; the final proposal intended that the ASX and SGX bourses would have continued functioning separately. The merger was blocked by Treasurer of Australia Wayne Swan on 8 April 2011, on advice from the Foreign Investment Review Board that the proposed merger was not in the best interests of Australia.[21]”
For Topic Modeling we need to map each word to a unique ID through creating a dictionary:
And the created dictionary should be converted into a bag-of-words. We do that with doc2bow().
Next, we use Latent Dirichlet Allocation (LDA) which is a popular topic modeling technique because it assumes documents are produced from a mixture of topics. These topics then generate words based on their probability distribution. Set up the LDA model with the number of topics and train it on the corpus:
Finally, we can print the topics and their word distributions from our text:
Discussion
Teamwork: How does the topic modeling method help researchers? What about the text summarization? What are some of the challenges and limitations of text analysis in your research field (material science)? Consider some of the factors that affect the quality and accuracy of text analysis, such as data availability, language diversity, and domain specificity. How do these factors pose problems or difficulties for text analysis in material science?
Challenge
Q: Use the Gensim library to perform topic modeling on the following text, print the original text and the list of topics and their keywords.
text = ” Perovskite nanocrystals have emerged as a promising class of materials for next-generation optoelectronic devices due to their unique properties. Their crystal structure allows for tunable bandgaps, which are the energy differences between occupied and unoccupied electronic states. This tunability enables the creation of materials that can absorb and emit light across a wide range of the electromagnetic spectrum, making them suitable for applications like solar cells, light-emitting diodes (LEDs), and lasers. Additionally, perovskite nanocrystals exhibit high photoluminescence efficiencies, meaning they can efficiently convert absorbed light into emitted light, further adding to their potential for various optoelectronic applications.”
A:
PYTHON
import gensim
from gensim import corpora
from gensim.models import LdaModel
from gensim.utils import simple_preprocess
tokens = simple_preprocess(text)
dictionary = corpora.Dictionary([tokens])
corpus = [dictionary.doc2bow(tokens)]
model = LdaModel(corpus, num_topics=2, id2word=dictionary)
print(text)
print(model.print_topics())
Challenge
Q: Use the genism to perform topic modeling on the following two different texts and provide a comparison.
text1 = “Perovskite nanocrystals have emerged as a promising class of materials for next-generation optoelectronic devices due to their unique properties. Their crystal structure allows for tunable bandgaps, which are the energy differences between occupied and unoccupied electronic states. This tunability enables the creation of materials that can absorb and emit light across a wide range of the electromagnetic spectrum, making them suitable for applications like solar cells, light-emitting diodes (LEDs), and lasers. Additionally, perovskite nanocrystals exhibit high photoluminescence efficiencies, meaning they can efficiently convert absorbed light into emitted light, further adding to their potential for various optoelectronic applications.”
text2 = “Graphene is a one-atom-thick sheet of carbon atoms arranged in a honeycomb lattice. It is a remarkable material with unique properties, including high electrical conductivity, thermal conductivity, mechanical strength, and optical transparency. Graphene has the potential to revolutionize various fields, including electronics, photonics, and composite materials. Due to its excellent electrical conductivity, graphene is a promising candidate for next-generation electronic devices, such as transistors and sensors. Additionally, its high thermal conductivity makes it suitable for heat dissipation applications.”
A: After storing the two texts in text1 and text2, preprocess the text (e.g., tokenization, stop word removal, stemming/lemmatization). Split the texts into documents:
PYTHON
import gensim
from gensim import corpora
documents = [text1.split(), text2.split()]
# Create a dictionary:
dictionary = corpora.Dictionary(documents)
# Create a corpus (bag of words representation):
corpus = [dictionary.doc2bow(doc) for doc in documents]
# Train the LDA model (adjust num_topics as needed):
lda_model = gensim.models.LdaModel(corpus, id2word=dictionary, num_topics=3, passes=20)
# Print the original texts:
print("Original Texts:")
print(f"Text 1:\n{text1}\n")
print(f"Text 2:\n{text2}\n")
# Identify shared and distinct keywords for each topic:
print("Topics and Keywords:")
for topic in lda_model.show_topics(formatted=False):
print(f"\nTopic {topic[0]}:")
topic_words = [w[0] for w in topic[1]]
print(f"Text 1 Keywords:", [w for w in topic_words if w in text1])
print(f"Text 2 Keywords:", [w for w in topic_words if w in text2])
# Explain the conceptual similarity:
print("\nConceptual Similarity:")
print("Both texts discuss novel materials (perovskite nanocrystals and graphene) with unique properties. While the specific applications and functionalities differ slightly, they both highlight the potential of these materials for various technological advancements.")Original Texts:
Text 1: Perovskite nanocrystals have emerged as a promising class of materials for next-generation optoelectronic devices due to their unique properties. Their crystal structure allows for tunable bandgaps, which are the energy differences between occupied and unoccupied electronic states. This tunability enables the creation of materials that can absorb and emit light across a wide range of the electromagnetic spectrum, making them suitable for applications like solar cells, light-emitting diodes (LEDs), and lasers. Additionally, perovskite nanocrystals exhibit high photoluminescence efficiencies, meaning they can efficiently convert absorbed light into emitted light, further adding to their potential for various optoelectronic applications.
Text 2: Graphene is a one-atom-thick sheet of carbon atoms arranged in a honeycomb lattice. It is a remarkable material with unique properties, including high electrical conductivity, thermal conductivity, mechanical strength, and optical transparency. Graphene has the potential to revolutionize various fields, including electronics, photonics, and composite materials. Due to its excellent electrical conductivity, graphene is a promising candidate for next-generation electronic devices, such as transistors and sensors. Additionally, its high thermal conductivity makes it suitable for heat dissipation applications.
Topics and Keywords:
Topic 0:
Text 1 Keywords: ['applications', 'devices', 'material', 'optoelectronic', 'properties']
Text 2 Keywords: ['applications', 'conductivity', 'electronic', 'graphene', 'material', 'potential']
Topic 1:
Text 1 Keywords: ['bandgaps', 'crystal', 'electronic', 'properties', 'structure']
Text 2 Keywords: ['conductivity', 'electrical', 'graphene', 'material', 'properties']
Topic 2:
Text 1 Keywords: ['absorption', 'emit', 'light', 'spectrum']
Text 2 Keywords: ['conductivity', 'graphene', 'material', 'optical', 'potential']Conceptual Similarity:
Both texts discuss novel materials (perovskite nanocrystals and graphene) with unique properties. While the specific applications and functionalities differ slightly (optoelectronic devices vs. electronic devices), they both highlight the potential of these materials for various technological advancements. Notably, both topics identify “material,” “properties,” and “applications” as keywords, suggesting a shared focus on the materials’ characteristics and their potential uses. Additionally, keywords like “electronic,” “conductivity,” and “potential” appear in both texts within different topics, indicating a conceptual overlap in exploring the electronic properties and potential applications of these materials.
Challenge
Q: Use the Gensim library to perform topic modeling on the following text print the original text and the list of topics and their keywords.
text = “Natural language processing (NLP) is a subfield of computer science, information engineering, and artificial intelligence concerned with the interactions between computers and human (natural) languages, in particular how to program computers to process and analyze large amounts of natural language data. Challenges in natural language processing frequently involve speech recognition, natural language understanding, and natural language generation.”
A:
PYTHON
import gensim
from gensim import corpora
from gensim.models import LdaModel
from gensim.utils import simple_preprocess
tokens = simple_preprocess(text)
dictionary = corpora.Dictionary([tokens])
corpus = [dictionary.doc2bow(tokens)]
model = LdaModel(corpus, num_topics=2, id2word=dictionary)
print(text)
print(model.print_topics())
output = Natural language processing (NLP) is a subfield of computer science, information engineering, and artificial intelligence concerned with the interactions between computers and human (natural) languages, in particular how to program computers to process and analyze large amounts of natural language data. Challenges in natural language processing frequently involve speech recognition, natural language understanding, and natural language generation.
[(0, '0.051*"natural" + 0.051*"language" + 0.051*"processing" + 0.027*"nlp" + 0.027*"challenges" + 0.027*"speech" + 0.027*"recognition" + 0.027*"understanding" + 0.027*"generation" + 0.027*"frequently"'), (1, '0.051*"natural" + 0.051*"language" + 0.051*"computers" + 0.027*"interactions" + 0.027*"between" + 0.027*"human" + 0.027*"languages" + 0.027*"particular" + 0.027*"program" + 0.027*"process"')]
Challenge of using small size corpus
The warning message “too few updates, training might not converge”) arises when you are using a very small corpus for topic modeling with Latent Dirichlet Allocation (LDA) in Gensim. LDA relies on statistical analysis of documents to discover hidden topics. With a limited corpus (one document in your case), there aren’t enough data points for the model to learn robust topics. Increasing the number of documents (corpus size) generally improves the accuracy and convergence of LDA models.
3.3. Text Summarization
Text summarization in NLP is the process of creating a concise and coherent version of a longer text document, preserving its key information. There are two primary approaches to text summarization:
- Extractive Summarization: This method involves identifying and extracting key sentences or phrases directly from the original text to form the summary. It is akin to creating a highlight reel of the most important points.
- Abstractive Summarization: This approach goes beyond mere extraction; it involves understanding the main ideas and then generating new, concise text that captures the essence of the original content. It is similar to writing a synopsis or an abstract for a research paper.
In the next part of the workshop, we will explore advanced tools like transformers, which can generate summaries that are more coherent and closer to what a human might write. Transformers use models like BERT and GPT to understand the context and semantics of the text, allowing for more sophisticated abstractive summaries.
Challenge
Q: Fill in the blanks with the correct terms related to text summarization:
- —— summarization selects sentences directly from the original text, while —— summarization generates new sentences.
- —— are advanced tools used for generating more coherent and human-like summaries.
- The —— and —— models are examples of transformers that understand the context and semantics of the text.
- —— summarization can often create summaries that are more —— and coherent than —— methods.
- Advanced summarization tools use —— and —— to interpret and condense text.
A:
Extractive summarization selects sentences directly from the original text, while abstractive summarization generates new sentences.
Transformers are advanced tools used for generating more coherent and human-like summaries.
The BERT and GPT models are examples of transformers that understand the context and semantics of the text.
Abstractive summarization can often create summaries that are more concise and coherent than extractive methods.
Advanced summarization tools use machine learning and natural language processing to interpret and condense text.
Callout
In the rapidly evolving field of NLP, summarization tasks are increasingly being carried out using transformer-based models due to their advanced capabilities in understanding context and generating coherent summaries. Tools like Gensim’s summarization module
have become outdated and were removed in its 4.0 release (source), as they relied on extractive methods that simply selected parts of the existing text, which is less effective compared to the abstractive approach of transformers. These cutting-edge transformer models, which can create concise and fluent summaries by generating new sentences, are leading to the gradual disappearance of older, less efficient summarization methods.
Key Points
- Named Entity Recognition (NER) is crucial for identifying and categorizing key information in text, such as names of people, organizations, and locations.
- Topic Modeling helps uncover the underlying thematic structure in a large corpus of text, which is beneficial for summarizing and understanding large datasets.
- Text Summarization provides a concise version of a longer text, highlighting the main points, which is essential for quick comprehension of extensive research material.
Content from Word Embedding
Last updated on 2024-05-10 | Edit this page
Estimated time: 16 minutes
Overview
Questions
- What is a vector space in the context of NLP?
- How can I visualize vector space in a 2D model?
- How can I use embeddings and how do embeddings capture the meaning of words?
Objectives
- Be able to explain vector space and how it is related to text analysis.
- Identify the tools required for text embeddings.
- To explore the Word2Vec algorithm and its advantages over traditional models.
4.1. Introduction to Vector Space & Embeddings:
We have discussed how tokenization works and how it is important in text analysis, however, this is not the whole story of preprocessing. For conducting robust and reliable text analysis with NLP models, vectorization and embedding are required after tokenization. To understand this concept, we first talk about vector space.
Vector space models represent text data as vectors, which can be used in various machine learning algorithms. Embeddings are dense vectors that capture the semantic meanings of words based on their context.
Discussion
Teamwork: Discuss how tokenization affects the representation of text in vector space models. Consider the impact of ignoring common words (stop words) and the importance of word order.

A: Ignoring stop words might lead to loss of some contextual information but can also reduce noise. Preserving word order can be crucial for understanding the meaning, especially in languages with flexible syntax.
Tokenization is a fundamental step in the processing of text for vector space models. It involves breaking down a string of text into individual units, or “tokens,” which typically represent words or phrases. Here’s how tokenization impacts the representation of text in vector space models:
- Granularity: Tokenization determines the granularity of text representation. Finer granularity (e.g., splitting on punctuation) can capture more nuances but may increase the dimensionality of the vector space.
- Dimensionality: Each unique token becomes a dimension in the vector space. The choice of tokenization can significantly affect the number of dimensions, with potential implications for computational efficiency and the “curse of dimensionality.”
- Semantic Meaning: Proper tokenization ensures that semantically significant units are captured as tokens, which is crucial for the model to understand the meaning of the text.
Ignoring common words, or “stop words,” can also have a significant impact:
Noise Reduction: Stop words are often filtered out to reduce noise since they usually don’t carry important meaning and are highly frequent (e.g., “the,” “is,” “at”).
Focus on Content Words: By removing stop words, the model can focus on content words that carry the core semantic meaning, potentially improving the performance of tasks like information retrieval or topic modeling.
Computational Efficiency: Ignoring stop words reduces the dimensionality of the vector space, which can make computations more efficient.
The importance of word order is another critical aspect:
Contextual Meaning: Word order is essential for capturing the syntactic structure and meaning of a sentence. Traditional bag-of-words models ignore word order, which can lead to a loss of contextual meaning.
Phrase Identification: Preserving word order allows for the identification of multi-word expressions and phrases that have distinct meanings from their constituent words.
Word Embeddings: Advanced models like word embeddings (e.g., Word2Vec) and contextual embeddings (e.g., BERT) can capture word order to some extent, leading to a more nuanced understanding of text semantics.
In summary, tokenization, the treatment of stop words, and the consideration of word order are all crucial factors that influence how text is represented in vector space models, affecting both the quality of the representation and the performance of downstream tasks.
Tokenization Vs. Vectorization Vs. Embedding
Initially, tokenization breaks down text into discrete elements, or tokens, which can include words, phrases, symbols, and even punctuation, each represented by a unique numerical identifier. These tokens are then mapped to vectors of real numbers within an n-dimensional space, a process that is part of embedding. During model training, these vectors are adjusted to reflect the semantic similarities between tokens, positioning those with similar meanings closer together in the embedding space. This allows the model to grasp the nuances of language and transforms raw text into a format that machine learning algorithms can interpret, paving the way for advanced text analysis and understanding.
4.2. Bag of Words & TF-IDF:
Feature extraction in machine learning involves creating numerical features that describe a document’s relationship to its corpus. Traditional methods like Bag-of-Words and TF-IDF count words or n-grams, with the latter assigning weights based on a word’s importance, calculated by Term Frequency (TF) and Inverse Document Frequency (IDF). TF measures a word’s importance within a document, while IDF assesses its rarity across the corpus.
The product of TF and IDF gives the TF-IDF score, which balances a word’s frequency in a document against its commonness in the corpus. This approach helps to highlight significant words while diminishing the impact of commonly used words like “the” or “a.”
- BoW “encodes the total number of times a document uses each word in the associated corpus through the CounterVectorizer.”
- TF-IDF “creates features for each document based on how often each word shows up in a document versus the entire corpus.
- source
Discussion
Teamwork: Discuss how each method represents the importance of words and the potential impact on sentiment analysis.
A: To compare the Bag of Words (BoW) and Term Frequency-Inverse Document Frequency (TF-IDF) methods in representing text data and their implications for sentiment analysis.
Data Collection: Gather a corpus of product reviews. For this activity, let’s assume we have a list of reviews stored in a variable called reviews. Clean the text data by removing punctuation, converting to lowercase, and possibly removing stop words. Use a vectorizer to convert the reviews into a BoW representation.
Discuss how BoW represents the frequency of words without considering the context or rarity across documents. Use a vectorizer to convert the same reviews into a TF-IDF representation. Discuss how TF-IDF represents the importance of words by considering both the term frequency and how unique the word is across all documents.
Teamwork
Sentiment Analysis Implications:
Analyze a corpus of product reviews using both BoW and TF-IDF. Consider how the lack of context in BoW might affect sentiment analysis. Evaluate whether TF-IDF’s emphasis on unique words improves the model’s ability to understand sentiment.
Share Findings: Groups should present their findings, highlighting the strengths and weaknesses of each method.
PYTHON
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
# Sample corpus of product reviews
reviews = [
"Great product, really loved it!",
"Bad quality, totally disappointed.",
"Decent product for the price.",
"Excellent quality, will buy again!"
]
# Initialize the CountVectorizer for BoW
bow_vectorizer = CountVectorizer(stop_words='english')
# Fit and transform the reviews
bow_matrix = bow_vectorizer.fit_transform(reviews)
# Display the BoW matrix
print("Bag of Words Matrix:")
print(bow_matrix.toarray())
# Initialize the TfidfVectorizer for TF-IDF
tfidf_vectorizer = TfidfVectorizer(stop_words='english')
# Fit and transform the reviews
tfidf_matrix = tfidf_vectorizer.fit_transform(reviews)
# Display the TF-IDF matrix
print("\nTF-IDF Matrix:")
print(tfidf_matrix.toarray())The BoW matrix shows the frequency of each word in the reviews, disregarding context and word importance. The TF-IDF matrix shows the weighted importance of words, giving less weight to common words and more to unique ones.
In sentiment analysis, BoW might misinterpret sentiments due to ignoring context, while TF-IDF might capture nuances better by emphasizing words that are significant in a particular review.
By comparing BoW and TF-IDF, participants can gain insights into how each method processes text data and their potential impact on NLP tasks like sentiment analysis. This activity encourages critical thinking about feature representation in machine learning models.
4.3. Word2Vec Algorithm:
More advanced techniques like Word2Vec and GLoVE, as well as feature learning during neural network training, have also been developed to improve feature extraction.
Word2Vec uses neural networks to learn word associations from large text corpora. It has two architectures: Skip-Gram and Continuous Bag-of-Words (CBOW).
After training, it discards the final layer and outputs word embeddings that capture context. These embeddings capture the context of words, making similar contexts yield similar embeddings. Post-data preprocessing, these numerical features can be used in various NLP models for tasks like classification or named entity recognition.
Now let’s see how this framework can be used in practice. First import required libraries: Start by importing necessary libraries like gensim for Word2Vec and nltk for tokenization. Next, prepare the data: Tokenize your text data into words.
PYTHON
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Sample text
text = "Tokenization splits text into words. Embeddings capture semantic meaning."
# Tokenize the text
tokens = word_tokenize(text.lower())
Now train the model: Use the Word2Vec class from gensim to train your model on the tokenized sentences.
PYTHON
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Sample text
text = "Tokenization splits text into words. Embeddings capture semantic meaning."
# Tokenize the text
tokens = word_tokenize(text.lower())Retrieve Vectors: After training, use the model to get vectors for words of interest.
The code tokenizes the sample text, trains a Word2Vec model, and retrieves the vector for the word ‘embeddings’.
The resulting vector is a 50-dimensional representation of ‘embeddings’, capturing its context within the sample text. This vector can then be used in various NLP tasks to represent the semantic meaning of the word ‘embeddings’.
By understanding the roles of tokenization and embedding, we can better prepare text data for complex NLP tasks and build models that more accurately interpret human language.
Global Vectors for Word Representation (GLoVE)
GLoVE is a model for learning word embeddings, which are representations of words in the form of high-dimensional vectors. Unlike Word2Vec, which uses a neural network to learn word embeddings from local context information, GLoVE is designed to capture both global statistics and local context. Here’s how GLoVE stands out:
- Matrix Factorization: GLoVE uses matrix factorization on a word co-occurrence matrix that reflects how often each word appears in the context of every other word within a large corpus.
- Global Word-Word Co-Occurrence: It focuses on word-to-word co-occurrence globally across the entire corpus, rather than just within a local context window as in Word2Vec.
- Weighting Function: GLoVE employs a weighting function that helps to address the disparity in word co-occurrence frequencies, giving less weight to rare and frequent co-occurrences.
The main difference between GLoVE and Word2Vec is that GLoVE is built on the idea that word meanings can be derived from their co-occurrence probabilities with other words, and hence it incorporates global corpus statistics, whereas Word2Vec relies more on local context information. This allows GLoVE to effectively capture both the semantic and syntactic relationships between words, making it powerful for various natural language processing tasks.
Key Points
- Tokenization is crucial for converting text into a format usable by machine learning models.
- BoW and TF-IDF are fundamental techniques for feature extraction in NLP.
- Word2Vec and GloVE generate embeddings that encapsulate word meanings based on context and co-occurrence, respectively.
- Understanding these concepts is essential for building effective NLP models that can interpret and process human language.
Content from Transformers for Natural Language Processing
Last updated on 2024-05-15 | Edit this page
Estimated time: 12 minutes
Overview
Questions
- How do Transformers work?
- How can I use Transformers for text analysis?
Objectives
- To be able to describe Transformers’ architecture.
- To be able to implement sentiment analysis, and text summarization using transformers.
Transformers have revolutionized the field of NLP since their introduction by the Google team in 2017. Unlike previous models that processed text sequentially, Transformers use an attention mechanism to process all words at once, allowing them to capture context more effectively. This parallel processing capability enables Transformers to handle long-range dependencies and understand the nuances of language better than their predecessors. For now, try to recognize the building blocks of the general structure of a transformer
5.1. Introduction to Artificial Neural Networks
To understand how Transformers work we also need to learn about artificial neural networks (ANNs). Imagine a neural network as a team of workers in a factory. Each worker (neuron) has a specific task (processing information), and they pass their work along to the next person in line until the final product (output) is created.
Just like a well-organized assembly line, a neural network processes information in stages, with each neuron contributing to the final result.
Activity
Teamwork: Take a look at the architecture of a simple ANN below. Identify the underlying layers and components of this ANN and add the correct name label to each one.
In the context of machine learning, a multilayer perceptron (MLP) is indeed a fully connected multi-layer neural network and is a classic example of a feedforward artificial neural network (ANN). It typically includes an input layer, one or more hidden layers, and an output layer. When an MLP has more than one hidden layer, it can be considered a deep ANN, part of a broader category known as deep learning.
Summation and Activation Function
If we zoom into a neuron in the hidden layer, we can see the mathematical operations (weights summation and activation function). An input is transformed at each hidden layer node through a process that multiplies the input (x_i) by learned weights (w_i), adds a bias (b), and then applies an activation function to determine the node’s output. This output is either passed on to the next layer or contributes to the final output of the network. Essentially, each node performs a small calculation that, when combined with the operations of other nodes, allows the network to process complex patterns and data.
Backpropagation is an algorithmic cornerstone in the training of ANNs, serving as a method for optimizing weights and biases through gradient descent. Conceptually, it is akin to an iterative refinement process where the network’s output error is propagated backward, layer by layer, using the chain rule of calculus. This backward flow of error information allows for the computation of gradients, which inform the magnitude and direction of adjustments to be made to the network’s parameters. The objective is to iteratively reduce the differences between the predicted output and the actual target values. This systematic adjustment of parameters, guided by error gradients, incrementally leads to a more accurate ANN model.
Challenge
Teamwork: When we talk about ANNs, we also consider their parameters. But what are the parameters? Draw a small neural network with 3 following layers: x1
- Input Layer: 3 neurons
- Hidden Layer: 4 neurons
- Output Layer: 1 neurons
- Connect each neuron in the input layer to every neuron in the hidden layer (next layer). How many connections (weights) do we have?
- Now, add a bias for each neuron in the hidden layer. How many biases do we have?
- Repeat the process for the hidden layer to the output layer.
- (3 { neurons} x 4 { neurons} + 4{ biases}) = 16
- (4 { neurons} x 1 { neurons} + 1{ biases}) = 5
- Total parameters for this network: (16 + 5 = 21)
Challenge
Q: Add another hidden layer with 4 neurons to the previous ANN and calculate the number of parameters.
We would add: - (4 * 4) weights from the first to the second hidden layer - (4) biases for the new hidden layer - (4 * 1) weights from the second hidden layer to the output layer (we already counted the biases for the output layer)
That’s an additional (16 + 4 = 20) parameters, bringing our total to (21 + 20 = 41) parameters.
5.2. Transformers
As mentioned in the introduction, Most of the recent NLP models are built based on Transformers. Building on our understanding of ANNs, let’s explore the architecture of transformers. Transformers consist of several key components that work together to process and generate data.
Activity
Teamwork: We go back to the first figure of this episode. In the simplified schematic below, write the function of each component in the allocated textbox:
A:
Briefly, we can say:
- Encoder: Processes input text into contextualized representations, enabling the understanding of the context within the input sequence. It is like the ‘listener’ in a conversation, taking in information and understanding it.
- Decoder: Generates output sequences by translating the contextualized representations from the encoder into coherent text, often using mechanisms like masked multi-head attention and encoder-decoder attention to maintain sequence order and coherence. This acts as the ‘speaker’ in the conversation, generating the output based on the information processed by the encoder.
- Positional Encoding: Adds unique information to each word embedding, indicating the word’s position in the sequence, which is essential for the model to maintain the order of words and understand their relative positions within a sentence
- Input Embedding: The input text is converted into vectors that the model can understand. Think of it as translating words into a secret code that the transformer can read.
- Output Embedding: Similar to input embedding, but for the output text. It translates the transformer’s secret code back into words we can understand.
- Softmax Output: Applies the softmax function to the final layer’s outputs to convert them into a probability distribution, which helps in tasks like classification and sequence generation by selecting the most likely next word or class. It is like choosing the best response in a conversation from many options.
Attention Mechanism
So far, we have learned what the architecture of a transformer block looks like. However, for simplicity, many parts of this architecture have not been considered.
In the following section, we will show the underlying components of a transformer.
For more details see source.
Attention mechanisms in transformers, allow LLMs to focus on different parts of the input text to understand context and relationships between words. The concept of ‘attention’ in encoders and decoders is akin to the selective focus of ‘fast reading,’ where one zeroes in on crucial information and disregards the irrelevant. This mechanism adapts to the context of a query, emphasizing different words or tokens based on the query’s intent. For instance, in the sentence “Sarah went to a restaurant to meet her friend that night,” the words highlighted would vary depending on whether the question is about the action (What?), location (Where?), individuals involved (Who?), or time (When?).
In transformer models, this selective focus is achieved through ‘queries,’ ‘keys,’ and ‘values,’ all represented as vectors. A query vector seeks out the closest key vectors, which are encoded representations of values. The relationship between words, like ‘where’ and ‘restaurant,’ is determined by their frequency of co-occurrence in sentences, allowing the model to assign greater attention to ‘restaurant’ when the query pertains to a location. This dynamic adjustment of focus enables transformers to process language with a nuanced understanding of context and relevance.
Discussion
Teamwork: Have you heard of any other applications of the Transformers rather than in NLPs? Explain why transformers can be useful for other AI applications. Share your thoughts and findings with other groups.
A: Transformers, initially popular in NLP, have found applications beyond text analysis. They excel in computer vision, speech recognition, and even genomics. Their versatility extends to music generation and recommendation systems. Transformers’ innovative architecture allows them to adapt to diverse tasks, revolutionizing AI applications.
Transformers in Text Translation
Imagine you want to translate the sentence “What time is it?” from English to German using a transformer. The input embedding layer converts each English word into a vector. The six layers of encoders process these vectors, understanding the context of the sentence. The six layers of decoders then start generating the German translation, one word at a time.
For each word, the Softmax output predicts the most likely next word in German. The output embedding layer converts these predictions back into readable German words. By the end, you get the German translation of “What time is it?” as “Wie spät ist es?”
Pipelines
The pipeline module from Hugging Face’s transformers library is a high-level API that simplifies the use of complex machine learning models for a variety of NLP tasks. It is a versatile tool for NLP tasks, enabling users to perform text generation, sentiment analysis, question answering, summarization, and translation with minimal code. By abstracting away the intricacies of model selection, tokenization, and output generation, the pipeline module makes state-of-the-art AI accessible to developers of all skill levels, allowing them to harness the power of language models efficiently and intuitively.
Transformers are essential for NLP tasks because they overcome the limitations of earlier models like recurrent neural networks (RNNs) and long short-term memory models (LSTMs), which struggled with long sequences and were computationally intensive respectively. Transformers, in contrast to the sequential input processing of RNNs, handle entire sequences simultaneously. This parallel processing capability enables data scientists to employ GPUs to train large language models (LLMs) based on transformers, which markedly decreases the duration of training.
5.3. Sentiment Analysis
Sentiment analysis is a powerful tool in NLP that helps determine the emotional tone behind the text. It is used to understand opinions, sentiments, emotions, and attitudes from various entities and classify them according to their polarity.
Activity
Teamwork: How do you categorize the following text in terms of positive and negative sounding? Select an Emoji.
“A research team has unveiled a novel ligand exchange technique that enables the synthesis of organic cation-based perovskite quantum dots (PQDs), ensuring exceptional stability while suppressing internal defects in the photoactive layer of solar cells.” source
Computer models can do this job for us! Let’s see how it works through a step-by-step example: First, install the required libraries and pipelines:
Now, initialize the sentiment analysis pipeline and analyze the sentiment of a sample text:
PYTHON
sentiment_pipeline = pipeline('sentiment-analysis')
text = " A research team has unveiled a novel ligand exchange technique that enables the synthesis of organic cation-based perovskite quantum dots (PQDs), ensuring exceptional stability while suppressing internal defects in the photoactive layer of solar cells."
sentiment = sentiment_pipeline(text)After the analysis is completed, you can print out the results:
PYTHON
print(f"Sentiment: {sentiment[0]['label']}, Confidence: {sentiment[0]['score']:.2f}")
# Output
Output: Sentiment: POSITIVE, Confidence: 1.00In this example, the sentiment analysis pipeline from the Hugging Face library is used to analyze the sentiment of a research paper abstract. The model predicts the sentiment as positive, negative, or neutral, along with a confidence score. This can be particularly useful for gauging the reception of research papers in a field.
Activity
Teamwork: Fill in the blanks to complete the sentiment analysis process: Install the __________ library for sentiment analysis. Use the __________ function to create a sentiment analysis pipeline. The sentiment analysis model will output a __________ and a __________ score.
VADRER
Valence Aware Dictionary and sEntiment Reasoner (VADER) is a lexicon and rule-based sentiment analysis tool that is particularly attuned to sentiments expressed in social media. VADER analyzes the sentiment of the text and returns a dictionary with scores for negative, neutral, positive, and a compound score that aggregates them. It is useful for quick sentiment analysis, especially on social media texts. Let’s how we can use this framework.
First, we need to import the SentimentIntensityAnalyzer module from VADER library:
PYTHON
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
# Initialize VADER sentiment intensity analyzer:
analyzer = SentimentIntensityAnalyzer()
# We use the same sample text:
text = " A research team has unveiled a novel ligand exchange technique that enables the synthesis of organic cation-based perovskite quantum dots (PQDs), ensuring exceptional stability while suppressing internal defects in the photoactive layer of solar cells."
# Now we can analyze sentiment:
vader_sentiment = analyzer.polarity_scores(text)
# Print the sentiment:
print(f"Sentiment: {vader_sentiment}")
Output: Sentiment: {'neg': 0.069, 'neu': 0.818, 'pos': 0.113, 'compound': 0.1779}Discussion
Teamwork: Which framework do you think could be more helpful for research applications? Elaborate your opinion. Share your thoughts with other team members.
A: Transformers use deep learning models that can understand context and nuances of language, making them suitable for complex and lengthy texts. They can be particularly useful for sentiment analysis of research papers, as they can understand the complex language and context often found in academic writing. This allows for a more nuanced understanding of the sentiment conveyed in the papers. VADER, on the other hand, is a rule-based model that excels in analyzing short texts with clear sentiment expressions, often found in social media.
Challenge
Use the transformers library to perform sentiment analysis on the following text:
“Perovskite nanocrystals have emerged as a promising class of materials for next-generation optoelectronic devices due to their unique properties. Their crystal structure allows for tunable bandgaps, which are the energy differences between occupied and unoccupied electronic states. This tunability enables the creation of materials that can absorb and emit light across a wide range of the electromagnetic spectrum, making them suitable for applications like solar cells, light-emitting diodes (LEDs), and lasers.”
Print the original text and the sentiment score and label. You can use the following code to load the transformers library and the pre-trained model and tokenizer for sentiment analysis:
A:
PYTHON
from transformers import pipeline
sentiment_analysis = pipeline("sentiment-analysis")
text = "This book is amazing. It is well-written, engaging, and informative. I learned a lot from reading it and I highly recommend it to anyone interested in natural language processing."
print(text)
print(sentiment_analysis(text))Output:
PYTHON
output: "Perovskite nanocrystals have emerged as a promising class of materials for next-generation optoelectronic devices due to their unique properties. Their crystal structure allows for tunable bandgaps, which are the energy differences between occupied and unoccupied electronic states. This tunability enables the creation of materials that can absorb and emit light across a wide range of the electromagnetic spectrum, making them suitable for applications like solar cells, light-emitting diodes (LEDs), and lasers."
[{'label': 'POSITIVE', 'score': 0.9998656511306763}]Challenge
Comparing Transformer with VADER on a large size text. Use the Huggingface library database.
5.4. Text Summarization
Text summarization is the process of distilling the most important information from a source (or sources) to produce an abbreviated version for a particular user and task. It can be broadly classified into two types: extractive and abstractive summarization.
Discussion
How extractive and abstractive summarization methods are different? Connect the following text boxes to the correct category. Share your results with other group members.
A:
Now, let’s see how to use the Hugging Face Transformers library to perform abstractive summarization. First, from the transformers import pipeline:
Input a sample text from an article from source:
text = “A groundbreaking research breakthrough in solar energy has propelled the development of the world’s most efficient quantum dot (QD) solar cell, marking a significant leap towards the commercialization of next-generation solar cells. This cutting-edge QD solution and device have demonstrated exceptional performance, retaining their efficiency even after long-term storage. Led by Professor Sung-Yeon Jang from the School of Energy and Chemical Engineering at UNIST, a team of researchers has unveiled a novel ligand exchange technique. This innovative approach enables the synthesis of organic cation-based perovskite quantum dots (PQDs), ensuring exceptional stability while suppressing internal defects in the photoactive layer of solar cells. Our developed technology has achieved an impressive 18.1% efficiency in QD solar cells,” stated Professor Jang. This remarkable achievement represents the highest efficiency among quantum dot solar cells recognized by the National Renewable Energy Laboratory (NREL) in the United States. The increasing interest in related fields is evident, as last year, three scientists who discovered and developed QDs, as advanced nanotechnology products, were awarded the Nobel Prize in Chemistry. QDs are semiconducting nanocrystals with typical dimensions ranging from several to tens of nanometers, capable of controlling photoelectric properties based on their particle size. PQDs, in particular, have garnered significant attention from researchers due to their outstanding photoelectric properties. Furthermore, their manufacturing process involves simple spraying or application to a solvent, eliminating the need for the growth process on substrates. This streamlined approach allows for high-quality production in various manufacturing environments. However, the practical use of QDs as solar cells necessitates a technology that reduces the distance between QDs through ligand exchange, a process that binds a large molecule, such as a ligand receptor, to the surface of a QD. Organic PQDs face notable challenges, including defects in their crystals and surfaces during the substitution process. As a result, inorganic PQDs with limited efficiency of up to 16% have been predominantly utilized as materials for solar cells. In this study, the research team employed an alkyl ammonium iodide-based ligand exchange strategy, effectively substituting ligands for organic PQDs with excellent solar utilization. This breakthrough enables the creation of a photoactive layer of QDs for solar cells with high substitution efficiency and controlled defects. Consequently, the efficiency of organic PQDs, previously limited to 13% using existing ligand substitution technology, has been significantly improved to 18.1%. Moreover, these solar cells demonstrate exceptional stability, maintaining their performance even after long-term storage for over two years. The newly-developed organic PQD solar cells exhibit both high efficiency and stability simultaneously. Previous research on QD solar cells predominantly employed inorganic PQDs,” remarked Sang-Hak Lee, the first author of the study. Through this study, we have demonstrated the potential by addressing the challenges associated with organic PQDs, which have proven difficult to utilize. This study presents a new direction for the ligand exchange method in organic PQDs, serving as a catalyst to revolutionize the field of QD solar cell material research in the future,” commented Professor Jang. The findings of this study, co-authored by Dr. Javid Aqoma Khoiruddin and Sang-Hak Lee, have been published online in Nature Energy on January 27, 2024. The research was made possible through the support of the ‘Basic Research Laboratory (BRL)’ and ‘Mid-Career Researcher Program,’ as well as the ‘Nano·Material Technology Development Program,’ funded by the National Research Foundation of Korea (NRF) under the Ministry of Science and ICT (MSIT). It has also received support through the ’Global Basic Research Lab Project.”
Now we can perform summarization and print the results:
PYTHON
summary = summarizer(text, max_length=130, min_length=30, do_sample=False)
# Print the summary:
print("Summary:", summary[0]['summary_text'])
Output:
Sumy for summarization
Sumy is a Python library for extractive summarization. It uses algorithms like LSA to rank sentences based on their importance and creates a summary by selecting the top-ranked sentences. We can see how it works in practice: We start with importing the PlaintextParser and LsaSummarizer modules:
PYTHON
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.lsa import LsaSummarizerTo create a parser we use the same text sample from an article from source:
PYTHON
parser = PlaintextParser.from_string(text, Tokenizer("english"))
# Next, we initialize the LSA summarize:
summarizer = LsaSummarizer()
# Summarize the text and print the results
summary = summarizer(parser.document, 5)
for sentence in summary:
print(sentence)
Output:Sumy extracts key sentences from the original text, which can be quicker but may lack the cohesiveness of an abstractive summary. On the other hand, Transformer is suitable for generating a new summary that captures the text’s essence in a coherent and often more readable form.
Activity
Teamwork: Which framework could be more useful for text summarizations in your field of research? Explain why?
A: Transformers are particularly useful for summarizing research papers and documents where understanding the context and generating a coherent summary is crucial. They can produce summaries that are not only concise but also maintain the narrative flow, making them more readable. Sumy, while quicker and less resource-intensive, is best suited for scenarios where extracting key information without the need for narrative flow is acceptable.
Challenge
Use the transformers library to perform text summarization on the following text [generated by Copilot]:
text: “Perovskite nanocrystals are a class of semiconductor nanocrystals that have attracted a lot of attention in recent years due to their unique optical and electronic properties. Perovskite nanocrystals have an ABX3 composition, where A is a monovalent cation (such as cesium, methylammonium, or formamidinium), B is a divalent metal (such as lead or tin), and X is a halide (such as chloride, bromide, or iodide). Perovskite nanocrystals can emit brightly across the entire visible spectrum, with tunable colors depending on their composition and size. They also have high quantum yields, fast radiative decay rates, and narrow emission line widths, making them ideal candidates for various optoelectronic applications. The first report of perovskite nanocrystals was published in 2014 by Protesescu et al., who synthesized cesium lead halide nanocrystals using a hot-injection method. They demonstrated that the nanocrystals had cubic or orthorhombic crystal structures, depending on the halide ratio, and that they exhibited strong photoluminescence with quantum yields up to 90%. They also showed that the emission wavelength could be tuned from 410 nm to 700 nm by changing the halide composition or the nanocrystal size. Since then, many other groups have developed various synthetic methods and strategies to control the shape, size, composition, and surface chemistry of perovskite nanocrystals. One of the remarkable features of perovskite nanocrystals is their defect tolerance, which means that they can maintain high luminescence even with a high density of surface or bulk defects. This is in contrast to other semiconductor nanocrystals, such as CdSe, which require surface passivation to prevent non-radiative recombination and quenching of the emission. The defect tolerance of perovskite nanocrystals is attributed to their electronic band structure, which has a large density of states near the band edges and a small effective mass of the charge carriers. These factors reduce the formation energy and the localization of defects and enhance the radiative recombination rate of the excitons. Another interesting aspect of perovskite nanocrystals is their weak quantum confinement, which means that their emission properties are not strongly affected by their size. This is because the exciton binding energy of perovskite nanocrystals is much larger than the quantum confinement energy, and thus the excitons are localized within a few unit cells regardless of the nanocrystal size. As a result, perovskite nanocrystals can exhibit narrow emission line widths even with a large size distribution, which simplifies the synthesis and purification processes. Moreover, perovskite nanocrystals can show dual emission from both the band edge and the surface states, which can be exploited for color tuning and white light generation. Perovskite nanocrystals have been applied to a wide range of photonic devices, such as light-emitting diodes, lasers, solar cells, photodetectors, and scintillators. Perovskite nanocrystals can offer high brightness, color purity, and stability as light emitters, and can be integrated with various substrates and architectures. Perovskite nanocrystals can also act as efficient light absorbers and charge transporters and can be coupled with other materials to enhance the performance and functionality of the devices. Perovskite nanocrystals have shown promising results in terms of efficiency, stability, and versatility in these applications. However, perovskite nanocrystals also face some challenges and limitations, such as the toxicity of lead, the instability under ambient conditions, the hysteresis and degradation under electrical or optical stress, and the reproducibility and scalability of the synthesis and fabrication methods. These issues need to be addressed and overcome to realize the full potential of perovskite nanocrystals in practical devices. Therefore, further research and development are needed to improve the material quality, stability, and compatibility of perovskite nanocrystals, and to explore new compositions, structures, and functionalities of these fascinating nanomaterials.”
A: You can use the following code to load the transformers library and the pre-trained model and tokenizer for text summarization:
Key Points
- Transformers revolutionized NLP by processing words in parallel through an attention mechanism, capturing context more effectively than sequential models
- The summation and activation function within a neuron transform inputs through weighted sums and biases, followed by an activation function to produce an output.
- Transformers consist of encoders, decoders, positional encoding, input/output embedding, and softmax output, working together to process and generate data.
- Transformers are not limited to NLP and can be applied to other AI applications due to their ability to handle complex data patterns.
- Sentiment analysis and text summarization are practical applications of transformers in NLP, enabling the analysis of emotional tone and the creation of concise summaries from large texts.
Content from Large Language Models
Last updated on 2024-05-12 | Edit this page
Estimated time: 12 minutes
Overview
Questions
- What are the main features of large language models?
- How is BERT different from GPT models?
- How can I use open-source LLMs, such as LLM examples in huggingface, for research tasks?
Objectives
- Be able to explain the structure of large language models and their main components
- Identify differences between BERT and GPT.
- Be able to use open-source LLMs, such as huggingface, for text summarization, classification, and generation.
6.1. Introduction to LLMs
Large Language Models (LLMs) have become a cornerstone of modern natural language processing (NLP). Since the introduction of the transformer architecture in 2017, LLMs have leveraged this design to achieve remarkable language understanding and generation capabilities. In the previous episode, we discussed the transformer architecture, which is integral to all LLMs, utilizing its encoder and decoder components to process language.
LLMs have several key features.
Challenge
Fill in the above feature placeholders. Discuss what are these key components. Explain the key features in detail and compare your thoughts with the other group members:
Transformer Architecture: A neural network design that uses self-attention mechanisms to weigh the influence of different parts of the input data.
Pre-training: involves teaching LLMs to anticipate words in sentences, using either bi-directional or uni-directional approaches, (based on the LLM type), without the need for understanding or experience.
Transformer Architecture: A neural network design that uses self-attention mechanisms to weigh the influence of different parts of the input data.
Pre-training: involves teaching LLMs to anticipate words in sentences, using either bi-directional or uni-directional approaches, (based on the LLM type), without the need for understanding or experience.
Word/Token Embedding: The process of converting words or phrases into numerical form (vectors) that computers can understand.
RECALL embedding?
Context Window: The range of words the model considers for predicting the next word or understanding the current word within a sentence.
Parameters: The aspects of the model that are learned from training data and determine the model’s behavior.
Transfer Learning: The process LLMs use to apply their prior knowledge to new tasks.
Thus, the completed graph will be:
We can categorize LLMs based on the transformer architecture. Let’s have another look into the transformer architecture, this time we categorize them based on the two main components: Encoder and Decoder. LLMs can be designed to handle different tasks based on their underlying transformer blocks and whether they have encoder-only, decoder-only, or encoder-decoder layers.
Challenge
How do you think we should connect each one of the following transformers to the correct color?
• Encoders are used for understanding tasks like sentence classification.
• Decoders excel in generative tasks like text generation.
• The combination of encoders and decoders in transformers allows them to be versatile and perform a variety of tasks, from translation to summarization, depending on the specific requirements of the task at hand.
Encoder Vs. Decoder and/or BERT Vs. GPT
We will see models like BERT use encoders for bidirectional understanding, and models like GPT use decoders for generating coherent text, making them suitable for chatbots or virtual assistants.
Discussion
Teamwork: Think of some examples of traditional NLP models, such as n-gram models, hidden Markov models, LSTMs, and RNNs. How do large language models differ from them in terms of architecture, data, and performance?
A: Traditional NLP models, such as n-gram models, hidden Markov models (HMMs), Long Short-Term Memory Networks (LSTMs), and Recurrent Neural Networks (RNNs), differ significantly from the recent LLMs. N-gram models predict the next item in a sequence based on the previous ‘n-1’ items without any deep understanding of context. HMMs are statistical models that output probabilities of sequences and are often used for tasks like part-of-speech tagging. LSTMs and RNNs are types of neural networks that can process sequences of data and are capable of learning order dependence in sequence prediction.
Compared to these traditional models, LLMs have several key differences: - Architecture: Novel LLMs use transformer architectures, which are more advanced than the simple recurrent units of RNNs or the gated units of LSTMs. Transformers use self-attention to weigh the influence of different parts of the input data, which is more effective for understanding context. - Data: Novel LLMs are trained on massive datasets, often sourced from the internet, which allows them to learn a wide variety of language patterns, common knowledge, and even reasoning abilities. Traditional models typically use smaller, more curated datasets. - Performance: Novel LLMs generally outperform traditional models in a wide range of language tasks due to their ability to understand and generate human-like text. They can capture subtleties and complexities of language that simpler models cannot, leading to more accurate and coherent outputs.
6.2. BERT
Bidirectional Encoder Representations from Transformers (BERT) is an LLM that uses an encoder-only architecture from transformers. It is designed to understand the context of a word based on all of its surroundings (bidirectional context). Let’s guess the missing words in the text below to comprehend the workings of BERT:
Challenge
Complete the following paragraph:
“BERT is a revolutionary language model that uses an ______ (encoder) to process words in a sentence. Unlike traditional models, it predicts words based on the ______ rather than in sequence. Its training involves ______, where words are intentionally hidden, or ______, and the model learns to predict them. This results in rich ______ that capture the nuanced meanings of words.”
“BERT is a revolutionary language model that uses an encoder to process words in a sentence. Unlike traditional models, it predicts words based on the context rather than in sequence. Its training involves self-supervised learning, where words are intentionally hidden, or ‘masked’, and the model learns to predict them. This results in rich embeddings that capture the nuanced meanings of words.”
Pre-training of language models involves a process where models like BERT and GPT learn to predict words in sentences without specific task training. This is achieved through methods like the Masked Language Model (MLM) for bi-directional models, which predict masked words using surrounding context. MLM in BERT predicts missing words in a sentence by masking them during training.
For Next Sentence Prediction (NSP) BERT learns to predict if two sentences logically follow each other.
6.3. GPT
Generative Pretrained Transformer (GPT) models, on the other hand, use a decoder-only architecture. They excel at generating coherent and contextually relevant text. Check the following table that summarizes three different LLMs. The middle column misses some information about GPT models. With the help of your teammates complete the table and explain the differences in the end.
Challenge
Write in the gray boxes with the correct explanations.
Discussion
Teamwork: From what you learned above how can you explain the differences between the three LLM types? Discuss in groups and share your answers.
A: We can see it as the processes of trying to understand a conversation (BERT), versus trying to decide what to say next in the conversation (GPT). BERT is like someone who listens to the entire conversation before and after a word to really understand its meaning.
For example, in the sentence “I ate an apple,” BERT would look at both “I ate an” and “apple” to figure out what “an” refers to. It’s trained by playing a game of ‘guess the missing word,’ where some words are hidden (masked) and it has to use the context to fill in the blanks.
GPT, on the other hand, is like a storyteller who only needs to know what was said before to continue the tale. It would take “I ate an” and predict that the next word might be “apple.” It learns by reading a lot of text and practicing how to predict the next word in a sentence.
Both are smart in their own ways, but they’re used for different types of language tasks. BERT is great for understanding the context of words, while GPT is excellent at generating new text based on what it’s seen before. The following schematics demonstrate their performing differences:
Models are often benchmarked using standardized datasets and metrics. The Holistic Evaluation of Language Models (HELM) by Stanford provides a comprehensive framework for evaluating LLMs across multiple dimensions.
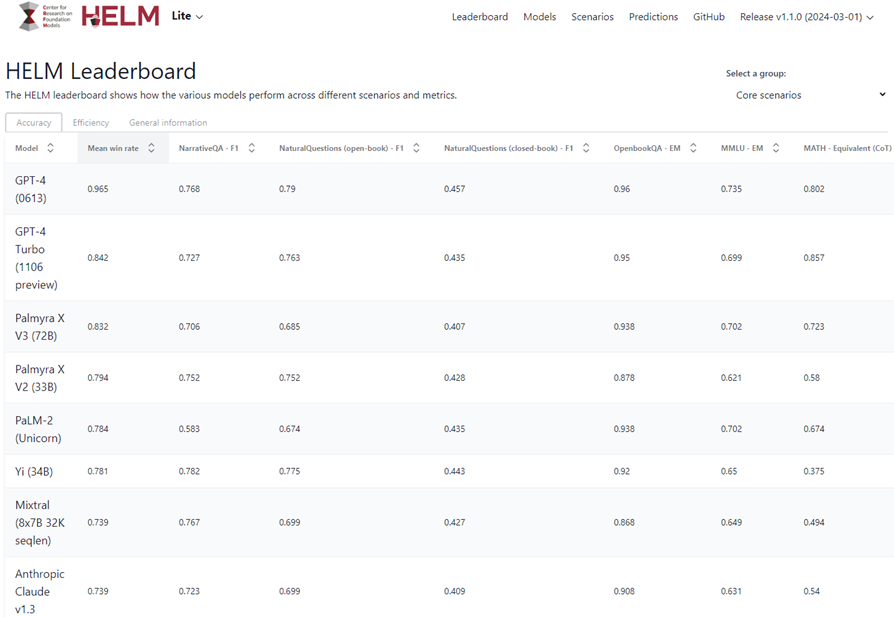
GPT-4 models are outperforming other LLM models in terms of accuracy.
Discussion
What are some examples of LLMs, and how are they trained and used for research tasks? Consider some of the main features and characteristics of LLMs, such as transformer architecture, self-attention mechanism, pre-training and fine-tuning, and embedding capabilities. How do these features enable LLMs to perform various NLP tasks, such as text classification, text generation, or question answering?
Challenge
How can we compare different LLMs? Are there any benchmarks?
A: Comparing Performance (Benchmarking): 1. Performance can be compared based on the model’s architecture, computational efficiency, and suitability for specific tasks. 2. Benchmarks and leaderboards (such as HELM) can provide insights into how different models perform on standardized datasets. 3. Community feedback and use-case studies can also inform the practical effectiveness of different LLMs.
6.4. Open-Source LLMs:
It is very important for researchers to openly have access to capable LLMs for their studies. Fortunately, some companies are supporting open-source LLMs. The BLOOM model, developed by the BigScience Workshop in collaboration with Hugging Face and other organizations, was released on July 6, 2022. It offers a wide range of model sizes, from 1.1 billion to 176 billion parameters, and is licensed under the open RAIL-M v1. BLOOM is known for its instruct models, coding capabilities, customization finetuning, and being open source. It is more openly accessible and benefits from a large community and extensive support.
On the other hand, the LLaMA model, developed by Meta AI, was released on February 24, 2023. It is available in four sizes: 7 billion, 13 billion, 33 billion, and 65 billion parameters. The license for LLaMA is restricted to noncommercial use, and access is primarily for researchers. Despite its smaller size, LLaMA is parameter-efficient and has outperformed GPT-3 on many benchmarks. However, its accessibility is more gated compared to BLOOM, and community support is limited to approved researchers.
Now let’s summarize what we learned here in the following table:

Hugging Face provides several different LLMs. Now we want to see how we can use an open-source model. using the Hugging Face datasets library and an open-source Large Language Model (LLM). We will go through the process of setting up the environment, installing necessary libraries, loading a dataset, and then using an LLM to process the data. We will start with setting up the environment.
Heads up
Before we begin, ensure that you have Python installed on your system. Python 3.6 or later is recommended. You can download Python from the official Python website.
Next, we will install the necessary libraries through the terminal or command prompt:
We use the squad dataset here, which is a question-answering dataset Question-answering is one of main goals of utilizing LLMs for research projects. When you run this script, the expected output should be the answer to the question based on the provided context. Here is how to load it:
PYTHON
from datasets import load_dataset
# Load the SQuAD dataset
squad_dataset = load_dataset('squad')
# Print the first example in the training set
print(squad_dataset['train'][0])
Now, we can load a pre-trained model from Hugging Face. For this example, let’s use the bert-base-uncased model, which is different from BLOOM and is suitable for question-answering tasks:
PYTHON
from transformers import AutoModelForQuestionAnswering, AutoTokenizer
# Load the tokenizer and model
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModelForQuestionAnswering.from_pretrained('bert-base-uncased')
We need to define the question and context here:
PYTHON
question = "What is the name of the university in Paris that was founded in 1257?"
context = "The University of Paris, founded in 1257, is often referred to as the Sorbonne after the college created by Robert de Sorbon. It is one of the world's oldest universities."Recall to be able to feed data into the model, we should already tokenize our data. Once we have our data tokenized, we can use the model to make predictions. Here is how to tokenize the first example:
PYTHON
# Tokenize the first example
Inputs = tokenizer(squad_dataset['train'][0]['question'], squad_dataset['train'][0]['context'], return_tensors='pt')
# Get model predictions
outputs = model(**inputs)
Note that the model outputs are raw logits. We need to convert these into an answer by selecting the tokens with the highest start and end scores:
PYTHON
import torch
# Find the tokens with the highest `start` and `end` scores
answer_start = torch.argmax(outputs.start_logits)
answer_end = torch.argmax(outputs.end_logits) + 1
# Convert tokens to the answer string
answer = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens (inputs['input_ids'][0][answer_start:answer_end]))
print(answer)
This will print the answer to the question based on the context provided in the dataset. In this case, the output would be:
This output indicates that the model has correctly identified “the Sorbonne” as the name of the university in Paris founded in 1257, based on the context given. Remember, the actual output may vary slightly depending on the model version and the specific weights used at the time of inference.
Discussion
Teamwork: What are the challenges and implications of LLMs, such as scalability, generalization, and social impact? What does it mean when an LLM hallucinates?
Challenge
Use the OpenAI library to access and use an open-source LLM for text summarization. You can use the following code to load the OpenAI library and the pre-trained model and tokenizer for text summarization:
PYTHON
import openai
openai.api_key = "sk-<your_api_key>"
text_summarizer = openai.Completion.create(engine="davinci", task="summarize")Use the text_summarizer to summarize the following text.
“Perovskite nanocrystals are a class of semiconductor nanocrystals, which exhibit unique characteristics that separate them from traditional quantum dots. Perovskite nanocrystals have an ABX3 composition where A = cesium, methylammonium (MA), or formamidinium (FA); B = lead or tin; and X = chloride, bromide, or iodide. Their unique qualities largely involve their unusual band structure which renders these materials effectively defect-tolerant or able to emit brightly without surface passivation. This is in contrast to other quantum dots such as CdSe which must be passivated with an epitaxially matched shell to be bright emitters. In addition to this, lead-halide perovskite nanocrystals remain bright emitters when the size of the nanocrystal imposes only weak quantum confinement. This enables the production of nanocrystals that exhibit narrow emission linewidths regardless of their polydispersity. The combination of these attributes and their easy-to-perform synthesis has resulted in numerous articles demonstrating the use of perovskite nanocrystals as both classical and quantum light sources with considerable commercial interest. Perovskite nanocrystals have been applied to numerous other optoelectronic applications such as light-emitting diodes, lasers, visible communication, scintillators, solar cells, and photodetectors. The first report of perovskite nanocrystals was published in 2014 by Protesescu et al., who synthesized cesium lead halide nanocrystals using a hot-injection method. They showed that the nanocrystals can emit brightly when excited by ultraviolet or blue light, and their colors are tunable across the entire visible spectrum by changing the halide from chloride (UV/blue) to bromide (green) and iodide (red). They also demonstrated that the nanocrystals can be incorporated into thin films and show high photoluminescence quantum yields (PLQYs) of up to 90%. Since then, many other synthetic methods have been developed to produce perovskite nanocrystals with different shapes, sizes, compositions, and surface ligands. Some of the common methods include ligand-assisted reprecipitation, antisolvent precipitation, solvothermal synthesis, microwave-assisted synthesis, and microfluidic synthesis. Perovskite nanocrystals can be classified into different types based on their structure, dimensionality, and composition. The most common type is the three-dimensional (3D) perovskite nanocrystals, which have a cubic or orthorhombic crystal structure and a band gap that depends on the halide content. The 3D perovskite nanocrystals can be further divided into pure halide perovskites (such as CsPbX3) and mixed halide perovskites (such as CsPb(Br/I)3), which can exhibit color tuning, anion exchange, and halide segregation phenomena. Another type is the two-dimensional (2D) perovskite nanocrystals, which have a layered structure with organic cations sandwiched between inorganic perovskite layers. The 2D perovskite nanocrystals have a quantum well-like band structure and a band gap that depends on the thickness of the perovskite layers. The 2D perovskite nanocrystals can also be mixed with 3D perovskite nanocrystals to form quasi-2D perovskite nanocrystals, which can improve the stability and emission efficiency of the nanocrystals. A third type is the metal-free perovskite nanocrystals, which replace the metal cations (such as Pb or Sn) with other elements (such as Bi or Sb). The metal-free perovskite nanocrystals have a lower toxicity and higher stability than the metal-based perovskite nanocrystals, but they also have a lower PLQY and a broader emission linewidth. The development of perovskite nanocrystals in the past few years has been remarkable, with significant advances in synthesis, characterization, and application. However, there are still some challenges and opportunities for further improvement. One of the major challenges is the stability of perovskite nanocrystals, which are sensitive to moisture, oxygen, heat, light, and electric fields. These factors can cause degradation, phase transition, and non-radiative recombination of the nanocrystals, resulting in reduced emission intensity and color stability. Several strategies have been proposed to enhance the stability of perovskite nanocrystals, such as surface passivation, encapsulation, doping, alloying, and embedding in matrices. Another challenge is the toxicity of perovskite nanocrystals, which are mainly composed of lead, a heavy metal that can cause environmental and health hazards. Therefore, there is a need to develop lead-free or low-lead perovskite nanocrystals that can maintain the high performance and tunability of the lead-based ones. Some of the promising candidates include tin-based, bismuth-based, and antimony-based perovskite nanocrystals. A third challenge is the scalability and integration of perovskite nanocrystals, which are essential for practical applications. There is a need to develop cost-effective and large-scale synthesis methods that can produce high-quality and uniform perovskite nanocrystals. Moreover, there is a need to develop efficient and reliable fabrication techniques that can integrate perovskite nanocrystals into various devices and platforms. In conclusion, perovskite nanocrystals are a fascinating class of nanomaterials that have shown remarkable potential for various photonic applications. They have unique properties such as defect tolerance, high quantum yield, fast radiative decay, and narrow emission linewidth in weak confinement, which make them ideal candidates for light emission devices. They also have a wide color tunability from ultraviolet to near-infrared regions, which makes them suitable for various wavelength-dependent applications. However, there are still some challenges that need to be overcome, such as stability, toxicity, scalability, and integration. Therefore, further research and development are needed to address these issues and to explore new opportunities for perovskite nanocrystals in the field of nanophotonics.
Print the summarized text.
Challenge
Use the huggingface library to access and use an open-source domain-specific LLM for text classification. You can use the following code to load the huggingface library and the pre-trained model and tokenizer for text classification:
Use the text_classifier to classify the following text into one of the categories: metals, ceramics, polymers, or composites. Print the text and the predicted category and score.
PYTHON
Text: "Polyethylene is a thermoplastic polymer that consists of long chains of ethylene monomers. It is one of the most common and widely used plastics in the world. It has many applications, such as packaging, bottles, containers, films, pipes, and cables. Polyethylene can be classified into different grades based on its density, molecular weight, branching, and crystallinity."A:
PYTHON
from transformers import pipeline
text_classifier = pipeline("text-classification")
text = "Polyethylene is a thermoplastic polymer that consists of long chains of ethylene monomers. It is one of the most common and widely used plastics in the world. It has many applications, such as packaging, bottles, containers, films, pipes, and cables. Polyethylene can be classified into different grades based on its density, molecular weight, branching, and crystallinity."
print(text)
print(text_classifier(text))
output: "Polyethylene is a thermoplastic polymer that consists of long chains of ethylene monomers. It is one of the most common and widely used plastics in the world. It has many applications, such as packaging, bottles, containers, films, pipes, and cables. Polyethylene can be classified into different grades based on its density, molecular weight, branching, and crystallinity."
"[{'label': 'polymers', 'score': 0.9987659454345703}]"Challenge
Use the huggingface library to access and use an open-source LLM for text generation. You can use the following code to load the huggingface library and the pre-trained model and tokenizer for text generation:
Use the text_generator to generate a paragraph of text based on the following prompt: “The applications of nanomaterials in material science are”. Print the prompt and the generated text.
PYTHON
from transformers import pipeline
text_generator = pipeline("text-generation")
prompt = "The applications of nanomaterials in material science are"
generated_text = text_generator(prompt)[0]['generated_text']
print(prompt)
print(generated_text)
output: "The applications of nanomaterials in material science are
The applications of nanomaterials in material science are diverse and promising. Nanomaterials are materials that have at least one dimension in the nanometer range (1-100 nm). Nanomaterials can exhibit novel physical, chemical, and biological properties that are different from their bulk counterparts, such as high surface area, quantum confinement, enhanced reactivity, and tunable functionality. Nanomaterials can be used for various purposes in material science, such as improving the performance and functionality of existing materials, creating new materials with unique properties, and enabling new functionalities and devices. Some examples of nanomaterials applications in material science are:
- Nanocomposites: Nanomaterials can be incorporated into other materials, such as polymers, metals, ceramics, or biomaterials, to form nanocomposites that have improved mechanical, thermal, electrical, optical, or magnetic properties. For instance, carbon nanotubes can be used to reinforce polymer composites and increase their strength, stiffness, and conductivity.
- Nanocoatings: Nanomaterials can be used to coat the surface of other materials, such as metals, glass, or plastics, to provide them with enhanced protection, durability, or functionality. For example, titanium dioxide nanoparticles can be used to coat glass and make it self-cleaning, anti-fogging, and anti-bacterial.
- Nanosensors: Nanomaterials can be used to sense and measure various physical, chemical, or biological parameters, such as temperature, pressure, strain, pH, or biomolecules. For example, gold nanoparticles can be used to detect and quantify the presence of specific DNA sequences or proteins by changing their color or fluorescence.
- Nanomedicine: Nanomaterials can be used for various biomedical applications, such as drug delivery, imaging, diagnosis, or therapy. For example, magnetic nanoparticles can be used to deliver drugs to specific target sites in the body by using an external magnetic field, or to enhance the contrast of magnetic resonance imaging (MRI).
Key Points
- LLMs are based on the transformer architecture.
- BERT and GPT have distinct approaches to processing language.
- Open source LLMs provide transparency and customization for research applications.
- Benchmarking with HELM offers a holistic view of model performance.
Content from Domain-Specific LLMs
Last updated on 2024-05-20 | Edit this page
Estimated time: 12 minutes
Overview
Questions
- How can tune the LLMs to be domain-specific?
- What are some available approaches to empower LLMs solve specific research problems?
- Which approach should I use for my research?
- What are the challenges and trade-offs of domain-specific LLMs?
Objectives
- Be able to identify approaches by which LLMs can be tuned for solving research problems.
- Be able to use introductory approaches for creating domain-specific LLMs.
7.1. Introduction to DSL (Available Approaches)
To enhance the response quality of an LLM for solving specific problems we need to use strategies by which we can tune the LLM. Generally, there are four ways to enhance the performance of LLMs:
1. Prompt Optimization:
To elicit specific and accurate responses from LLMs by designing prompts strategically.
- Zero-shot Prompting: This is the simplest form of prompting where the LLM is given a task or question without any context or examples. It relies on the LLM’s pre-existing knowledge to generate a response.
“What is the capital of France?” The LLM would respond with “Paris” based on its internal knowledge.
- Few-shot Prompting: In this technique, the LLM is provided with a few examples to demonstrate the expected response format or content.
To determine sentiment, you might provide examples like “I love sunny days. (+1)” and “I hate traffic. (-1)” before asking the LLM to analyze a new sentence.
2. Retrieval Augmented Generation (RAG):
To supplement the LLM’s generative capabilities with information retrieved from external databases or documents.
- Retrieval: The LLM queries a database to find relevant information that can inform its response.
If asked about recent scientific discoveries, the LLM might retrieve articles or papers on the topic.
- Generation: After retrieving the information, the LLM integrates it into a coherent response.
Using the retrieved scientific articles, the LLM could generate a summary of the latest findings in a particular field.
3. Fine-Tuning:
To adapt a general-purpose LLM to excel at a specific task or within a particular domain.
- Language Modeling Task Fine-Tuning: This involves training the LLM on a large corpus of text to improve its ability to predict the next word or phrase in a sentence.
An LLM fine-tuned on legal documents would become better at generating text that resembles legal writing.
- Supervised Q&A Fine-Tuning: Here, the LLM is trained on a dataset of question-answer pairs to enhance its performance on Q&A tasks.
An LLM fine-tuned with medical Q&A pairs would provide more accurate responses to health-related inquiries.
4. Training from Scratch:
Builds a model specifically for a domain, using relevant data from the ground up.
Discussion
Teamwork: Which approach do you think is more computation-intensive? Which is more accurate? How are these qualities related? Evaluate the trade-offs between fine-tuning and other approaches.
Discussion
Teamwork: What is DSL and why are they useful for research tasks? Think of some examples of NLP tasks that require domain-specific LLMs, such as literature review, patent analysis, or material discovery. How do domain-specific LLMs improve the performance and accuracy of these tasks?

7.2. Prompting
Prompting is a technique employed to craft concise and clear instructions that guide the LLM in generating more accurate domain-specific outputs. In many cases, it does not coding but keep in mind that the quality of the input critically influences the output’s quality. It is a relatively easy and fast DSL method for harnessing LLM’s capabilities. We can see how it works through the following example:
PYTHON
Install the Hugging Face libraries
!pip install transformers datasets
from transformers import pipeline
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli")
# Example research question
question = "What is the role of CRISPR-Cas9 in genome editing?"
# Candidate topics to classify the question
topics = ["Biology", "Technology", "Healthcare", "Genetics", "Ethics"]
# Perform zero-shot classification
result = classifier(question, candidate_labels=topics)
# Output the results
print(f"Question: {question}")
print("Classified under topics with the following scores:")
for label, score in zip(result['labels'], result['scores']):
print(f"{label}: {score:.4f}")Which tool do researchers require?
For research applications where highly reliable answers are crucial, Prompt Engineering combined with Retrieval-Augmented Generation (RAG) is often the most suitable approach. This combination allows for flexibility and high-quality outputs by leveraging both the generative capabilities of LLMs and the precision of domain-specific data sources:
When fine-tuning a BERT model from Hugging Face, for instance, it is essential to approach the process with precision and care.
Begin by thoroughly understanding BERT’s architecture and the specific task at hand to select the most suitable model variant and hyperparameters.
Prepare your dataset meticulously, ensuring it is clean, well-represented, and split correctly to avoid data leakage and overfitting.
Hyperparameter selection, such as learning rates and batch sizes, should be made with consideration, and regularization techniques like dropout should be employed to enhance the model’s ability to generalize.
Evaluate the model’s performance using appropriate metrics and address any class imbalances with weighted loss functions or similar strategies. Save checkpoints to preserve progress and document every step of the fine-tuning process for transparency and reproducibility.
Ethical considerations are paramount; strive for a model that is fair and unbiased. Ensure compliance with data protection regulations, especially when handling sensitive information.
Lastly, manage computational resources wisely and engage with the Hugging Face community for additional support. Fine-tuning is iterative, and success often comes through continuous experimentation and learning.
Challenge
Check the following structure. Guess which optimization strategy is represented in these architectures.
RAG addresses the challenge of real-time data fetching by merging the generative talents of these models with the ability to consult a broad document corpus, enhancing their responses. The potential for live-RAG in chatbots suggests a future where AI can conduct on-the-spot searches, access up-to-date information, and rival search engines in answering timely questions.
Discussion
Teamwork: What are the challenges and trade-offs of domain-specific LLMs, such as data availability, model size, and complexity?
Consider some of the factors that affect the quality and reliability of domain-specific LLMs, such as the amount and quality of domain-specific data, the computational resources and time required for training or fine-tuning, and the generalization and robustness of the model. How do these factors pose problems or difficulties for domain-specific LLMs and how can we overcome them?
Discussion
What are some available approaches for creating domain-specific LLMs, such as fine-tuning and knowledge distillation?
Consider some of the main steps and techniques for creating domain-specific LLMs, such as selecting a general LLM, collecting and preparing domain-specific data, training or fine-tuning the model, and evaluating and deploying the model. How do these approaches differ from each other and what are their advantages and disadvantages?
Now let’s try One-shot and Few-shot prompting examples and see how they can help us to enhance the sensitivity of the LLM to our field of study: One-shot prompting involves providing the model with a single example to follow. It is like giving the model a hint about what you expect. We will go through an example using Hugging Face’s transformers library:
PYTHON
from transformers import pipeline
# Load a pre-trained model and tokenizer
model_name = "gpt2"
generator = pipeline('text-generation', model=model_name)
# One-shot example
prompt = "Translate 'Hello, how are you?' to French:\nBonjour, comment ça va?\nTranslate 'I am learning new things every day' to French:"
result = generator(prompt, max_length=100)
# Output the result
print(result[0]['generated_text'])In this example, we provide the model with one translation example and then ask it to translate a new sentence. The model uses the context from the one-shot example to generate the translation.
But what if we have a Few-Shot Prompting? Few-shot prompting gives the model several examples to learn from. This can improve the model’s ability to understand and complete the task.
Here is how you can implement few-shot prompting:
PYTHON
from transformers import pipeline
# Load a pre-trained model and tokenizer
model_name = "gpt2"
generator = pipeline('text-generation', model=model_name)
# Few-shot examples
prompt = """\
Q: What is the capital of France?
A: Paris.
Q: What is the largest mammal?
A: Blue whale.
Q: What is the human body's largest organ?
A: The skin.
Q: What is the currency of Japan?
A:"""
result = generator(prompt, max_length=100)
# Output the result
print(result[0]['generated_text'])In this few-shot example, we provide the model with three question-answer pairs before posing a new question. The model uses the pattern it learned from the examples to answer the new question.
Challenge
To summarize this approach in a few steps, fill in the following gaps: 1. Choose a Model: Select a — model from Hugging Face that suits your task.
Load the Model: Use the — function to load the model and tokenizer.
Craft Your Prompt: Write a — that includes one or more examples, depending on whether you’re doing one-shot or few-shot prompting.
Generate Text: Call the — with your prompt to generate the —.
Review the Output: Check the generated text to see if the model followed the — correctly.
Choose a Model: Select a pre-trained model from Hugging Face that suits your task.
Load the Model: Use the pipeline function to load the model and tokenizer.
Craft Your Prompt: Write a prompt that includes one or more examples, depending on whether you’re doing one-shot or few-shot prompting.
Generate Text: Call the generator with your prompt to generate the output.
Review the Output: Check the generated text to see if the model followed the examples correctly.
Remember, the quality of the output heavily depends on the quality and relevance of the examples you provide. It’s also important to note that larger models tend to perform better at these tasks due to their greater capacity to understand and generalize from examples.
Key Points
- Domain-specific LLMs are essential for tasks that require specialized knowledge.
- Prompt engineering, RAG, fine-tuning, and training from scratch are viable approaches to create DSLs.
- A mixed prompting-RAG approach is often preferred for its balance between performance and resource efficiency.
- Training from scratch offers the highest quality output but requires significant resources.
Content from Wrap-up and Final Project
Last updated on 2024-05-21 | Edit this page
Estimated time: 12 minutes
Overview
Questions
- What are the core concepts and techniques we’ve learned about NLP and LLMs?
- How can these techniques be applied to solve real-world problems?
- What are the future directions and opportunities in NLP?
Objectives
- To be able to synthesize the key concepts from each episode.
- To plan a path for further learning and exploration in NLP and LLMs.
8.1. Takeaway from This Workshop
We have covered a vast landscape of NLP, starting with the basics and moving towards the intricacies of LLMs. Here is a brief recap to illustrate our journey:
- Text Preprocessing: Imagine cleaning a dataset of tweets for sentiment analysis. We learned how to remove noise and prepare the text for accurate classification.
- Text Analysis: Consider the task of extracting key information from news articles. Techniques like Named Entity Recognition helped us identify and categorize entities within the text.
- Word Embedding: We explored how words can be converted into vectors, enabling us to capture semantic relationships, as seen in the Word2Vec algorithm.
- Transformers and LLMs: We saw how transformers like BERT and GPT can be fine-tuned for tasks such as summarizing medical research papers and showcasing their power and flexibility.
Quiz
A) Gensim
B) Word2Vec
C) Named Entity Recognition
D) Part-of-Speech Tagging
E) Stop-words Removal
F) Transformers
G) Bag of Words
H) Tokenization
I) BERT
J) Lemmatization
1. A masked language model for NLP tasks that require a good contextual understanding of an entire sequence.
[ ] A - [ ] B - [ ] C - [ ] D - [ ] E - [ ] F - [ ] G - [ ] H - [ ] I - [ ] J
2. “A process of reducing words to their root form, enabling the analysis of word frequency.
[ ] A - [ ] B - [ ] C - [ ] D - [ ] E - [ ] F - [ ] G - [ ] H - [ ] I - [ ] J
3. An algorithm that uses neural networks to understand the relationships and meanings in human language.
[ ] A - [ ] B - [ ] C - [ ] D - [ ] E - [ ] F - [ ] G - [ ] H - [ ] I - [ ] J
4. A technique for identifying the parts of speech for each word in a given sentence.
[ ] A - [ ] B - [ ] C - [ ] D - [ ] E - [ ] F - [ ] G - [ ] H - [ ] I - [ ] J
5. A process where an algorithm takes a string of text and identifies relevant nouns that are mentioned in that string.
[ ] A - [ ] B - [ ] C - [ ] D - [ ] E - [ ] F - [ ] G - [ ] H - [ ] I - [ ] J
6. A library that provides tools for machine learning and statistical modeling.
[ ] A - [ ] B - [ ] C - [ ] D - [ ] E - [ ] F - [ ] G - [ ] H - [ ] I - [ ] J
7. A model that predicts the next word in a sentence based on the words that come before it.
[ ] A - [ ] B - [ ] C - [ ] D - [ ] E - [ ] F - [ ] G - [ ] H - [ ] I - [ ] J
8. One of the first steps in text analysis, which involves breaking down text into individual elements.
[ ] A - [ ] B - [ ] C - [ ] D - [ ] E - [ ] F - [ ] G - [ ] H - [ ] I - [ ] J
9. A technique that groups similar words together in vector space.
[ ] A - [ ] B - [ ] C - [ ] D - [ ] E - [ ] F - [ ] G - [ ] H - [ ] I - [ ] J
10. A method for removing commonly used words that carry little meaning.
[ ] A - [ ] B - [ ] C - [ ] D - [ ] E - [ ] F - [ ] G - [ ] H - [ ] I - [ ] J
A:
1. A masked language model for NLP tasks that require a good contextual understanding of an entire sequence.
[ ] A - [ ] B - [ ] C - [ ] D - [ ] E - [ ] F - [ ] G - [ ] H - [X] I - [ ] J
2. “A process of reducing words to their root form, enabling the analysis of word frequency.
[ ] A - [ ] B - [ ] C - [ ] D - [ ] E - [ ] F - [ ] G - [ ] H - [ ] I - [X] J
3. An algorithm that uses neural networks to understand the relationships and meanings in human language.
[ ] A - [ ] B - [ ] C - [ ] D - [ ] E - [X] F - [ ] G - [ ] H - [ ] I - [ ] J
4. A technique for identifying the parts of speech for each word in a given sentence.
[ ] A - [ ] B - [ ] C - [X] D - [ ] E - [ ] F - [ ] G - [ ] H - [ ] I - [ ] J
5. A process where an algorithm takes a string of text and identifies relevant nouns that are mentioned in that string.
[ ] A - [ ] B - [X] C - [ ] D - [ ] E - [ ] F - [ ] G - [ ] H - [ ] I - [ ] J
6. A library that provides tools for machine learning and statistical modeling.
[X] A - [ ] B - [ ] C - [ ] D - [ ] E - [ ] F - [ ] G - [ ] H - [ ] I - [ ] J
7. A model that predicts the next word in a sentence based on the words that come before it.
[ ] A - [ ] B - [ ] C - [ ] D - [ ] E - [X] F - [ ] G - [ ] H - [ ] I - [ ] J
8. One of the first steps in text analysis, which involves breaking down text into individual elements.
[ ] A - [ ] B - [ ] C - [ ] D - [ ] E - [ ] F - [ ] G - [X] H - [ ] I - [ ] J
9. A technique that groups similar words together in vector space.
[ ] A - [X] B - [ ] C - [ ] D - [ ] E - [ ] F - [ ] G - [ ] H - [ ] I - [ ] J
10. A method for removing commonly used words that carry little meaning.
[ ] A - [ ] B - [ ] C - [ ] D - [X] E - [ ] F - [ ] G - [ ] H - [ ] I - [ ] J
Discussion
Field of Interest
Teamwork: Share insights on how NLP can be applied in your field of interest.
Environmental Science
- NLP for Climate Change Research: How can NLP help in analyzing large volumes of research papers on climate change to identify trends and gaps in the literature?
- Social Media Analysis for Environmental Campaigns: Discuss the use of sentiment analysis to gauge public opinion on environmental policies.
- Automating Environmental Compliance: Share insights on how NLP can streamline the process of checking compliance with environmental regulations in corporate documents.
Education
- Personalized Learning: Explore the potential of NLP in creating personalized learning experiences by analyzing student feedback and performance.
- Content Summarization: Discuss the benefits of using NLP to summarize educational content for quick revision.
- Language Learning: Share thoughts on the role of NLP in developing language learning applications that adapt to the learner’s proficiency level.
Capstone Project: Build and Optimize a DSL Question-Answering System
From the Hugging Face model hub, use the GPT-2 model to build a question-answering system that can answer questions specific to a particular field (e.g., environmental science). I. Test your model using the zero-shot prompting technique. II. Test your model using the few-shot prompting technique. Ask the same question as in the zero-shot test and compare the generated answers.
A.I:
Context Example: Environmental science and climate change
PYTHON
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# Initialize the tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# Since GPT-2 does not have a pad token, we set it to the eos_token
tokenizer.pad_token = tokenizer.eos_token
# Function to generate a response from the model
def get_model_response(question):
# Encode the prompt with an attention mask and padding
encoded_input = tokenizer.encode_plus(
question,
add_special_tokens=True,
return_tensors='pt',
padding='max_length', # Pad to max length
truncation=True,
max_length=100
)
# Generate the response with the attention mask and pad token id
outputs = model.generate(
input_ids=encoded_input['input_ids'],
attention_mask=encoded_input['attention_mask'],
pad_token_id=tokenizer.eos_token_id,
max_length=200,
num_return_sequences=1
)
# Decode and return the response
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return responseNow, we need to create a function that takes user inputs and provides answers:
PYTHON
# Main function to interact with the user
def main():
# Ask the user for their question
user_question = input("What is your question about climate change? ")
# Get the model's response
answer = get_model_response(user_question)
# Print the answer
print(f"AI: {answer}")
# Run the main function
if __name__ == "__main__":
main()For the second part of the project, We will use few-shot prompting by providing examples of questions and answers related to environmental topics.
A.II:
PYTHON
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# Initialize the tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# Set the pad token to the eos token for the tokenizer
tokenizer.pad_token = tokenizer.eos_token
# Function to generate a response from the model
def get_model_response(question):
# Construct the prompt with clear instructions and examples (*source*: generated by GPT4)
prompt = f"""
I am an AI trained to answer questions about climate change. Here are some examples:
Q: What causes climate change?
A: Climate change is primarily caused by the accumulation of greenhouse gases in the atmosphere due to human activities such as burning fossil fuels and deforestation.
Q: How does deforestation affect climate change?
A: Deforestation leads to increased carbon dioxide levels in the atmosphere because trees that absorb carbon dioxide are removed.
Q: What is climate change?
A: Climate change refers to significant changes in global temperatures and weather patterns over time.
Q: What causes global warming?
A: Global warming is primarily caused by the increase of greenhouse gases like carbon dioxide in the atmosphere due to human activities.
Q: How does deforestation affect climate change?
A: Deforestation contributes to climate change by reducing the number of trees that can absorb carbon dioxide, a greenhouse gas.
Q: Can planting trees help combat climate change?
A: Yes, planting trees can help mitigate climate change as trees absorb carbon dioxide from the atmosphere.
Q: What is renewable energy?
A: Renewable energy is derived from natural processes that are replenished constantly, like wind or solar power.
Q: Why is conserving water important for the environment?
A: Conserving water helps protect ecosystems, saves energy, and reduces the impact on water resources.
Q: What is sustainable living?
A: Sustainable living involves reducing one's carbon footprint by altering transportation methods, energy consumption, and diet.
Q: How do electric cars reduce pollution?
A: Electric cars produce fewer greenhouse gases and air pollutants than conventional vehicles.
Q: What is the impact of climate change on wildlife?
A: Climate change can alter habitats and food sources, leading to species migration and possible extinction.
Q: How does recycling help the environment?
A: Recycling reduces the need for raw materials, saves energy, and decreases pollution.
Q: What is carbon footprint?
A: A carbon footprint is the total amount of greenhouse gases emitted by an individual, organization, event, or product.
Q: Why is biodiversity important for the ecosystem?
A: Biodiversity boosts ecosystem productivity where each species has an important role to play.
Q: What are the effects of ocean acidification?
A: Ocean acidification can lead to the weakening of coral reefs and impact shell-forming marine life, disrupting the ocean's balance.
Q: How does climate change affect agriculture?
A: Climate change can alter crop yield, reduce water availability, and increase pests and diseases.
Q: What is the Paris Agreement?
A: The Paris Agreement is an international treaty aimed at reducing carbon emissions to combat climate change.
Q: How do fossil fuels contribute to global warming?
A: Burning fossil fuels releases large amounts of CO2, a major greenhouse gas, into the atmosphere.
Q: What is the significance of the ozone layer?
A: The ozone layer absorbs most of the sun's harmful ultraviolet radiation, protecting living organisms on Earth.
Q: What are green jobs?
A: Green jobs are positions in businesses that contribute to preserving or restoring the environment.
Q: How can we make our homes more energy-efficient?
A: We can insulate our homes, use energy-efficient appliances, and install smart thermostats to reduce energy consumption.
Q: What is the role of the United Nations in climate change?
A: The United Nations facilitates global climate negotiations and helps countries develop and implement climate policies.
Q: What are climate change mitigation and adaptation?
A: Mitigation involves reducing the flow of greenhouse gases into the atmosphere, while adaptation involves adjusting to current or expected climate change.
Q: How does urbanization affect the environment?
A: Urbanization can lead to habitat destruction, increased pollution, and higher energy consumption.
Q: What is a carbon tax?
A: A carbon tax is a fee imposed on the burning of carbon-based fuels, aimed at reducing greenhouse gas emissions.
Q: How does air pollution contribute to climate change?
A: Certain air pollutants like methane and black carbon have a warming effect on the atmosphere.
Q: What is an ecological footprint?
A: An ecological footprint measures the demand on Earth's ecosystems and compares it to nature's ability to regenerate resources.
Q: What are sustainable development goals?
A: Sustainable development goals are a collection of 17 global goals set by the United Nations to end poverty, protect the planet, and ensure prosperity for all.
Q: How does meat consumption affect the environment?
A: Meat production is resource-intensive and contributes to deforestation, water scarcity, and greenhouse gas emissions.
Q: What is an endangered species?
A: An endangered species is a type of organism that is at risk of extinction due to a drastic decline in population.
Q: How can businesses reduce their environmental impact?
A: Businesses can implement sustainable practices, reduce waste, use renewable energy, and invest in eco-friendly technologies.
Q: What is a climate model?
A: A climate model is a computer simulation used to predict future climate patterns based on different environmental scenarios.
Q: Why are wetlands important for the environment?
A: Wetlands provide critical habitat for many species, store floodwaters, and maintain surface water flow during dry periods.
Q: What is geoengineering?
A: Geoengineering is the deliberate large-scale intervention in the Earth’s climate system, aimed at mitigating the adverse effects of climate change.
Q: How does plastic pollution affect marine life?
A: Plastic pollution can injure or poison marine wildlife and disrupt marine ecosystems through ingestion and entanglement.
Q: What is a carbon sink?
A: A carbon sink is a natural or artificial reservoir that accumulates and stores carbon-containing chemical compounds for an indefinite period.
Q: How do solar panels work?
A: Solar panels convert sunlight into electricity through photovoltaic cells.
Q: What is the impact of climate change on human health?
A: Climate change can lead to health issues like heatstroke, allergies, and diseases spread by mosquitoes and ticks.
Q: What is a green economy?
A: A green economy is an economy that aims for sustainable development without degrading the environment.
Q: How does energy consumption contribute to climate change?
A: High energy consumption, especially from non-renewable sources, leads to higher emissions of greenhouse gases.
Q: What is the Kyoto Protocol?
A: The Kyoto Protocol is an international treaty that commits its parties to reduce greenhouse gas emissions.
Q: How can we protect coastal areas from rising sea levels?
A: We can protect coastal areas by restoring mangroves, building sea walls, and implementing better land-use policies.
Q: What is a heatwave, and how is it linked to climate change?
A: A heatwave is a prolonged period of excessively hot weather, which may become more frequent and intense due to climate change.
Q: How does climate change affect water resources?
A: Climate change can lead to changes in precipitation patterns, reduced snowpack, and increased evaporation rates.
Q: What is a carbon credit?
A: A carbon credit is a permit that allows the holder to emit a certain amount of carbon dioxide or other greenhouse gases.
Q: What are the benefits of wind energy?
A: Wind energy is a clean, renewable resource that reduces reliance on fossil fuels and decreases greenhouse gas emissions.
Q: What is an energy audit?
A: An energy audit is an assessment of energy use in a home or business to identify ways to improve efficiency and reduce costs.
Q: How do wildfires contribute to climate change?
A: Wildfires release stored carbon dioxide into the atmosphere and reduce the number of trees that can absorb CO2.
Q: What is a sustainable diet?
A: A sustainable diet involves consuming food that is healthy for individuals and sustainable for the environment.
Q: How does climate change affect the polar regions?
A: Climate change leads to melting ice caps, which can result in rising sea levels and loss of habitat for polar species.
Q: What is the role of youth in climate action?
A: Youth can play a crucial role in climate action through advocacy, innovation, and leading by example in sustainable practices.
Q: What is the significance of Earth Day?
A: Earth Day is an annual event to demonstrate support for environmental protection and promote awareness of environmental issues.
Q: {question}
A:"""
# Encode the prompt with an attention mask and padding
encoded_input = tokenizer.encode_plus(
prompt,
add_special_tokens=True,
return_tensors='pt',
padding='max_length', # Pad to max length
truncation=True,
max_length=100
)
# Generate the response with the attention mask and pad token id
outputs = model.generate(
input_ids=encoded_input['input_ids'],
attention_mask=encoded_input['attention_mask'],
pad_token_id=tokenizer.eos_token_id,
max_length=200,
num_return_sequences=1
)
# Decode and return the response
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response.split('A:')[1].strip() # Extract the AI's responseSimilar to the first part of the project, we need to create a user interface function:
PYTHON
def main():
user_question = input("Please enter your question about climate change: ")
# Get the model's response
answer = get_model_response(user_question)
# Print the answer
print(f"AI: {answer}")
# Run the main function
if __name__ == "__main__":
main()The model should provide a more relevant answer based on the few-shot examples provided. In this challenge, we used the GPT-2 model from Hugging Face’s transformers library to create a question-answering system. Few-shot prompting is employed to give the model context about environmental topics, which helps it generate more accurate answers to user queries.
However, you should note that the performance enhancement is not impressive sometimes and it may need fine-tuning to get more accurate responses.
8.2. Further Resources
For continued learning, here are detailed resources:
- Natural Language Processing Specialization (Coursera): A series of courses that cover NLP foundations, algorithms, and how to build NLP applications.
- Stanford NLP Group: Access to pioneering NLP research, datasets, and tools like Stanford Parser and Stanford POS Tagger.
- Hugging Face: A platform for sharing and collaborating on ML models, with a focus on democratizing NLP technologies.
- Kaggle: An online community for data scientists, offering datasets, notebooks, and competitions to practice and improve your NLP skills.
Each resource is a gateway to further knowledge, community engagement, and hands-on experience.
8.3. Feedback
Please help us improve by answering the following survey questions:
1. How would you rate the overall quality of the workshop?
[ ] Excellent, [ ] Good, [ ] Average, [ ] Below Average, [ ] Poor
2. Was the pace of the workshop appropriate?
[ ] Too fast, [ ] Just right, [ ] Too slow
3. How clear were the instructions and explanations?
[ ] Very clear, [ ] Clear, [ ] Somewhat clear, [ ] Not clear
4. What was the most valuable part of the workshop for you?
5. How can we improve the workshop for future participants?
Your feedback is crucial for us to evolve and enhance the learning experience.
Key Points
- Various NLP techniques from preprocessing to advanced LLMs are reviewed.
- NLPs’ transformative potential provides real-world applications in diverse fields.
- Few-shot learning can enhance the performance of LLMs for specific fields of research.
- Valuable resources are highlighted for continued learning and exploration in the field of NLP.